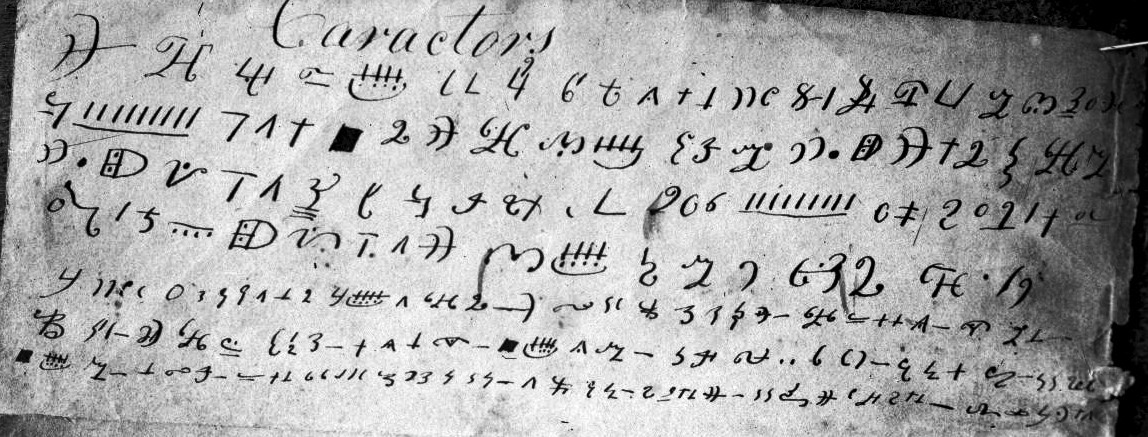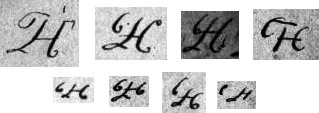It’s well-known that over the last two centuries, the quest for the mysterious “Money Pit” on Oak Island has yielded no sign of treasure while simultaneously consuming an inordinate quantity of diggers’ dollars – and if you can even think about all that without silently mouthing the phrase ‘ironically enough’, you have a huge amount of self-control. 😉
Yet despite all that ‘activity’, nothing of any actual substance about the whole curious enterprise that put or left the (so-called) pit there in the first place seems to have emerged. All that has been achieved is that (a) a small island has been ravaged by glinty-eyed treasure hunters, and (b) bookshelves have been filled with books that almost all manage to leave readers somehow less knowledgeable than when they began.
If you pause to reflect on the scale and prolonged fruitlessness of this archaeological disaster zone even momentarily, you’ll surely find it hard to prevent the two words “Epic” and “Fail” from lurching to the front of your mind. 😐

“The Curse of Oak Island”
Perhaps naturally enough, it seems that the (apparently obligatory) combination of determination, hubris, cupidity and stupidity that Oak Island treasure hunters have also makes them ideal Reality TV subjects, every bit as good as the Kardashians, TOWiE or whatever. Which is why the Canadian reality TV show “The Curse of Oak Island” (which premiered in 2014, and follows the Oak Island treasure hunt being pursued by Michigan brothers Marty and Rick Lagina) is now in its fantabulous 4th season. Will it ever end? (What do you think?)
Whatever you personally make of the whole Oak Island reality TV project, it is surely a brutal mirror to hold up to modern culture’s pox-plagued visage: for if all it boils down to is a fruitless search for something that nobody can describe and for which there seems to be no actual evidence, surely nobody involved can emerge the other side looking or smelling good. 🙁
Yet, curiously paralleling the Anton Transcript at the core of Mormonism, at the heart of the Money Pit mythology lies a cipher mystery that has had so much screen time in Z-grade historicalist documentaries that it practically has its own Equity card. Yes, I’m talking about a cipher that could get gigs on cruise ships.
As per normal, nobody knows whether or not this cipher is the real deal or merely Milli Vanilli. Moreover, it turns out that – just like the two versions of La Buse’s cryptogram – it also has a secret twin cipher (and nobody knows whether or not that’s real either), which we’ll (eventually) return to in Part 2. 🙂
Anyhoo, it’s time we all had a proper Cipher Mysteries look at the first (and infamous) Oak Island cipher…
The 80-foot Rock Cipher
Though most modern authors call it the “90-foot rock” cipher, this was claimed to have been found carved into a rock found eighty feet underground. As usual, I try to avoid following trends if I know they’re broken. 🙂
Regardless, the first documentary mention of it is in a 2nd June 1862 letter written by treasure hunter Jotham B. McCully of Truro, printed in the “Liverpool Transcript” in October 1862 in response to a critical article entitled “The Oak Island Folly”. McCully wrote “The Oak Island Diggings” to explain why he and the other treasure hunters were so convinced there was treasure in the Pit.
Bearing in mind that, according to other records, the original ‘Onslow Company’ search started in about 1795…:
“About seven years afterwards, Simeon Lynds, of Onslow, went down to Chester, and happening to stop with Mr. Vaughn, he was informed of what had taken place. He then agreed to get up a company, which he did, of about 25 or 30 men, and they commenced where the first left off, and sunk the pit 93 feet, finding a mark every ten feet. Some of them were charcoal, some putty, and one at 80 feet was a stone cut square, two feet long and about a foot thick, with several characters on it.”
According to this admirably source-heavy webpage, the stone was “yet to be seen in the chimney of an old house near the pit” (19th February 1863, Yarmouth Herald).
Then, the “remarkable” stone was then revealed to have been found “pretty far down in the pit, laying in the centre with the engraved side down”, and the house was revealed to be that of John Smith. It contained “a number of rudely cut letters and figures upon it. They were in hopes the inscription would throw some valuable light on their search, but unfortunately they could not decipher it, as it was either too badly cut or did not appear to be in their own vernacular.” (2nd January 1864, The Colonist, Halifax N.S.)
George Cooke, in a 27th January 1864 letter, described the marks as “rudely cut letters, figures or characters […]. I cannot recollect which, but they appear as if they had been scraped out by a blunt instrument, rather than cut with a sharp one.” He hoped that they could be deciphered in the future.
But what did the marks say? At that point in the cipher’s history, it seems nobody had decrypted it. But, according to the Oak Island Treasure Company prospectus (the copy transcribed on pp.215-225 of Geoff Bath’s “Maps, Mystery, and Interpretation” [Part 2] is dated 1894):
Many years afterwards, it was taken out of the chimney and taken to Halifax to have, if possible, the characters deciphered. One of the experts gave his reading of the inscriptions as follows: “Ten feet below are two million pounds buried.” We give this statement for what it is worth, but by no means claim that this is the correct interpretation. Apart from this however, the fact remains that the history and description of the stone as above given have never been disputed.”
Hence it was (apparently) first decrypted between 1864 and 1894.
Creighton’s Bookstore
The next mention of the “quaint carven stone” has it in Creighton’s Bookstore in Halifax, N.S.: “but the inscriptions were erased long ago after the stone had endured the blows from a bookbinder’s mallet. But at the time of the discovery of the stone the inscriptions were translated to read: ‘Ten feet below, 2,000,000 pounds lie buried.'” (29th April 1909, Fairbanks Daily News Miner).
Yet… the 19th August 1911 edition of Collier’s Magazine contains an eyewitness account supplied by Captain H.L. Bowdoin that departs somewhat from the dominant narrative. He wrote:
“While in Halifax we examined the stone found in the Money Pit, the characters on which were supposed to mean: “Ten feet below two million pounds lie buried.” The rock is of a basalt type hard and fine-grained.”
“There never were any characters on the rock found in the Money Pit. Because: (a) The rock, being hard, they could not wear off. (b) There are a few scratches, etc., made by Creighton’s employees, as they acknowledged, but there is not, and never was, a system of characters carved on the stone.”
There was backed up thoroughly by a 27th March 1935 eyewitness statement by Harry W. Marshall, who was the son of one of the owners of Creighton & Marshalls:
One of the Creighton’s was interested in the Oak Island Treasure Co. and had brought to the city a stone which I well remember seeing as a boy, and until the business was merged in 1919 in the present firm of Phillips & Marshall. The stone was about 2 feet long, 15 inches wide, and 10 inches thick, and weighed about 175 pounds. It had two smooth surfaces, with rough sides with traces of cement attached to them. Tradition said that it had been part of two fireplaces. The corners were not squared but somewhat rounded. The block resembled dark Swedish granite or fine grained porphyry, very hard, and with an olive tinge, and did not resemble any local stone. Tradition said that it had been found originally in the mouth of the “Money Pit”. While in Creighton’s possession some lad had cut his initials ‘J.M.” on one corner, but apart from this there was no evidence of any inscription either cut or painted on the stone. Creighton used the stone for a beating stone and weight. When the business was closed in 1919, Thos. Forhan, since deceased, asked for the stone, the history of which seems to have been generally known. When Marshall left the premises in 1919, the stone was left behind, but Forhan does not seem to have taken it. Search at Forhan’s business premises and residence two years ago disclosed no stone. The full history of the stone was written up in ‘the Suburban” about 1903 or 1904.
(Incidentally, people have searched for this issue of “The Suburban” but without any success.)
The two stones
Nobody seems to have dwelt much on what – to me, at least – is the most obvious problem with the above. Which is that we seem to be talking about two quite different stones here.
The first stone: “a stone cut square, two feet long and about a foot thick”, found eighty feet underground, and put into a chimney. Has curious writing on. Repeatedly described as having been “cut square”, like a “flagstone”.
The second stone: “2 feet long, 15 inches wide, and 10 inches thick”, “rounded” corners, found near the mouth of the Money Pit, and had been taken out of a chimney. Apparently has no writing on. “Basalt type hard and fine-grained” (Bowdoin), or “dark Swedish granite or fine grained porphyry, very hard, and with an olive tinge” (Marshall).
While it is entirely possible that the first stone was cut down to make it fit in John Smith’s chimney, the two descriptions don’t seem to fit each other in any other way either.
The most likely explanation to my mind is that we are talking about two entirely separate rocks both coming from the Money Pit, the first with marks roughly carved into it (and so perhaps a softer stone such as sandstone), and the second a much harder stone with no marks carved into it (the “JM” was added during its time in Halifax).
The first stone may therefore still be extant somewhere, perhaps in the garden of a Halifax house of a former treasure hunter.
Images of the 80-foot rock cipher
The short version is that there are no tracings or copies made from the object itself whose veracity we can be even remotely sure of: most of the images floating round the Internet are mock-ups of what people think it should look like.
Worse, the cipher’s plaintext seems to have changed along the way. Whereas in 1894 it was described as saying “Ten feet below are two million pounds buried”, this later changed into “Forty feet below two million pounds are buried” – note both the different depth and the different word order.
Where did this change? The first time we see the “forty feet” version is in a circa 1949 typewritten account of Oak Island by Reverend Austen Tremaize Kempton (which was never published):

Here’s what it looked like in print (I believe this is in Edward Rowe Snow’s 1949 “True Tales of Buried Treasure”):
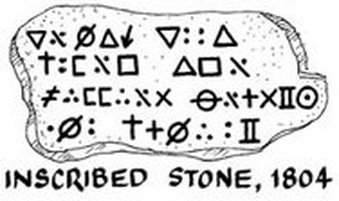
The person now often said to have decrypted the inscription was Dalhousie University Professor of Languages James Leitchi: there’s a good-sized page on him here.
Of course, one problem with this is that Leitchi was not actually an “old Irish school Master” but Swiss. However, he was (according to the timeline) a teacher at Halifax High School up until 1884: and we know that the stone was decrypted in Halifax before 1894.
Analyses and theories
Even though there is essentially zero doubt that the cipher as presented by Kempton (and then Snow) does indeed read “Forty feet below two million pounds are buried”, plenty of extra interpretations (typical “dual cipher” theories) have been put forward. One such was Dr. Wilhelm’s (modified) “At eighty guide maize or millet estuary or firth drain F”, described here.
Other webpages suggest that the letter shapes are all mathematical symbols, but this seems a bit lame to me: the shapes are just simple cipher shapes, nothing funky.
Other webpages suggest that Kempton faked the cipher, or that the whole thing is in fact a Masonic cryptogram or riddle. There’s also a theory by Keith Ranville, who also once put forward a Silk Road prostitution theory about the Voynich Manuscript
But I think all these theories and ideas are missing the big problem: which is that because we can’t account for the change in wording between the two versions of the cipher, we simply can’t comfortably trust the versions we have.
However, it’s entirely possible that I’ve missed something important in all the timelines. Please let me know if I have, thanks! 🙂