For far too long, Voynich researchers have (in my opinion) tried to use statistical analysis as a thousand-ton wrecking ball, i.e. to knock down the whole Voynich edifice in a single giant swing. Find the perfect statistical experiment, runs the train of thought, and all Voynichese’s skittles will clatter down. Strrrrike!
But… even a tiny amount of reflection should be enough to show that this isn’t going to work: the intricacies and contingencies of Voynichese shout out loud that there will be no single key to unlock this door. Right now, the tests that get run give results that are – at best – like peering through multiple layers of net curtains. We do see vague silhouettes, but nothing genuinely useful appears.
Whether you think Voynichese is a language, a cipher system, or even a generated text doesn’t really matter. We all face the same initial problem: how to make Voynichese tractable, by which I mean how to flatten it (i.e. regularize it) to the point where the kind of tests people run do stand a good chance of returning results that are genuinely revealing.
A staging point model
How instead, then, should we approach Voynichese?
The answer is perhaps embarrassingly obvious and straightforward: we should collectively design and implement statistical experiments that help us move towards a series of staging posts.
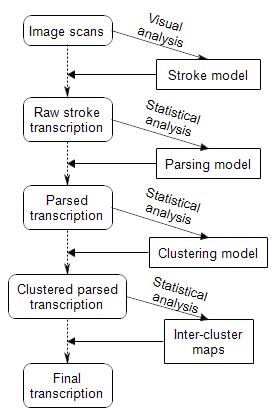
Each of the models on the right (parsing model, clustering model, and inter-cluster maps) should be driven by clear-headed statistical analysis, and would help us iterate towards the staging points on the left (parsed transcription, clustered parsed transcription, final transcription).
What I’m specifically asserting here is that researchers who perform statistical experiments on the raw stroke transcription in the mistaken belief that this is as good as a final transcription are simply wasting their time: there are too many confounding curtains in the way to ever see clearly.
The Curse, statistically
A decade ago, I first talked about “The Curse of the Voynich”: my book’s title was a way of expressing the idea that there was something about the way the Voynich Manuscript was constructed that makes fools of people who try to solve it.
Interestingly, it might well be that the diagram above explains what the Curse actually is: that all the while people treat the raw (unparsed, unclustered, unnormalized) transcription as if it were the final (parsed, clustered, normalized) transcription, their statistical experiments will continue to be confounded in multiple ways, and will show them nothing useful.
And is the VM ‘one single document’ rather than ‘a group of the writers’ or commissioning person’s favourite texts in one convenient book’ – the equivalent of a ‘commonplace book’ or (manuscript equivalent of) Sammelband – in which case there may be more than one original language.
Jackie Speel: I think that’s an example of the kind of question that you would only be able to answer at the end of the process, not at its start.
Even if the VM is coding multiple languages with a single alphabet/cipher/code, you should be able to discern distinct sections based on different patterns of usage…provided, as Nick says, you have an actual final, correct version of the text to work with. The inability to get a good final transcription is the “garbage in, garbage out” nature of Voynich statistical attacks.
My point was whether each section should be treated individually rather than assuming one single language throughout.
The defining feature of the claimed ‘translations’ is that they do not offer more than ‘a random selection of words.’
Jackie: you are partially right, insofar as there may well turn out to be tricky interplay between different models, e.g. even though all clusters use basically the same glyphs as each other, there’s a fair chance that some (e.g. A vs B) may use them in different ways.
NIck,
the contemporary statistical methods have very limited application, especially when used for language domain. . Their results in the situation “garbage in – garbage out” – which is well known fact in the computer world – actually do not depend on the method used :-).
On the other hand, there are very well known methods of Artificial Intelligence that are now frequently used in translations and cryptography. They can do our work better and faster. Neural networks for instance do the repeated iteration by testing the results and correcting the the inputs and testing again, e.t.c. until they meet the criteria.
I would say that the learning process is our weakest point. We do not want to end up as Gordon Rugg who started with valid hypothesis but failed when he tried ti re-engineer the VM.
Off topic but this post over on language log looks to be the sort of thing to interest folks here maybe? http://languagelog.ldc.upenn.edu/nll/?p=32464
Dear Nick,
if I understand you right you suggest to build a new perfect transcription variant for the Voynich manuscript. But it is unclear to me what the advantage of your transcription is? Even for your transcription it will be necessary to define what you accept as different types of strokes or variants of the same type of stroke. In the same way it will be necessary to define what letters exists for parsing the strokes. Which systematic errors made by Takahashi, Currier or the First study group did you see and how will you avoid them?
Torsten: no, you obviously don’t understand me right at all.
All the while we don’t know (for example) whether or not ee / eee / ii / iii / iv / iiv / iiv / aiv / aiiv / aiiiv / dy / qo / or / ar / ol / al / cth / ckh / cph / cfh / ok / ot / yk / yt are letters or composite groups standing in for tokens (whether these tokens are ciphers or not), all the analyses we do are flawed.
Similarly, all the while we don’t have a solid account of how the pages are clustered (Captain Currier’s A and B were useful first steps 40 years ago), people who do their statistical experiments on multiple clusters at the same time will produce results that are almost guaranteed to be uninterpretable.
So: what I call a “final transcription” would benefit from all these kinds of models at the same time, e.g. we would be able to say that “qochedy qodain” should in fact be parsed as “qo/ch/e/dy qo/dain”, where we can understand the construction of both words in terms of a specific B-dialect state machine. If you were then to do your own analyses of Voynichese with these kinds of models in mind (rather than on a raw stroke transcription), who knows what you would be able to see?
AI nowadays is really just pattern recognition and machine learning. But we don’t know what patterns to recognize in the Voynich Manuscript. Machine learning works well when the desired output is supplied, but, we don’t know what that should be; neither the plaint text, nor the language, nor even whether it is a language. People shouldn’t put faith in black-box approaches. At least with old fashioned statistics (and good old fashioned AI) you know what processing’s been done.
AI has been used by the way. Two people, using the same code (word2vec) arrived at contradictory results.
The only approach that I can see working is to use tried and tested statistical techniques. And the only approach I can see being accepted is one that’s been agreed beforehand by everyone.
So, what should be done first?
Nick,
None of what you suggest seems very different to the approach I took: cluster the pages, and use a state machine to describe the words. I’m open minded on the cluster boundaries, and whether and how the letters should be grouped within words: I constructed a state machine based upon EVA augmented with a “qo” glyph. The main problem I see is that running the same analysis with every possible glyph combination would take more time than I’m prepared to spend.
In any case, pages are clustered using bags of whole words, though it might be interesting to see whether using e.g. glyph pairs instead makes a significant difference.
Dear Nick,
did that mean that you would start with an already existing transcription as base for your staging point model? How would you handle for instance the fact that Takahashi reads sometimes ikh where other transcriptions read ckh? Would you allow to parse “qochedy qodain” differently for each cluster?
Statistical analyses are of course quite helpful, and have already provided important hints.
Where it goes completely wrong, is when one is not clear about the assumptions that have been made when doing the analysis. These assumptions fully condition the interpretation of the result.
This I see as the most important point in this blog post.
As the next step, one has to realise that the assumptions made at any point may be wrong. What any approach therefore needs to have is at least one arrow going back up.
Go back, fix mistaken assumptions and start again from this point.
Donald: what I’m trying to get across is that you (and Torsten, and countless others) tried to single-jump your way to a triple-jump distance.
That is, you assumed that your parsing is correct, and that your clustering is correct, and that your analysis is correct – but each of the steps individually requires much more collective analysis and reasoning than has been done to date.
For example: I have a substantial set of reasoning that suggests that what is transcribed as ckh and cth should instead be parsed as kch and tch, which would change a lot of statistics. Alter the way you parse the transcription, and all your numbers change drastically.
Torsten: the existing transcriptions need some tidying up, for sure. I understand that Rene has an unreleased transcription, for example: and back-converting Glen Claston’s transcription to EVA would also be a good comparative exercise. Glen felt that a number of features of the writing weren’t captured by EVA.
For me, however, I’ve been very concerned since 2006 that the way aiin groups have been transcribed is inadequate. The Beinecke curators turned down my requests to have a closer look at this, so the question remains unresolved. 🙁
Finally: as you point out, it is entirely possible that things could be parsed differently in different clusters, so this is a good question. I’ve long said that it is always better to perform analyses on a single cluster at a time, but I haven’t spent enough time thinking about how best to determine those clusters in a completely solid way. But the good news is that I suspect we will be able to determine the clusters without necessarily getting the parsing 100% locked down.
Dear Nick,
for each step of your staging model you have to interpret the text in some way. Only this way it is possible to define what tokens you allow for parsing or which clusters you will have. Moreover you do this with the initial assumption that it is possible to parse and to cluster the text of the manuscript. But maybe the reason that nothing genuinely useful appears is rather simple. Maybe the text of the Voynich manuscript doesn’t contain a genuine message. Before you can try to parse the the text you have to check if it is possible to parse it.
Concerning my analysis: I come to conclusion that it is not possible to parse the words since the text of the VMS only consists of similar glyph groups which are used near to each other. By doing so I stopped at the first step of your triple-jump distance since I come to the conclusion that the text of the VMS didn’t contain a genuine message.
Torsten: given that your explanation does not explain so many of the properties of Voynichese, why are you so convinced that you have not fallen into the trap I describe?
Dear Nick,
sorry, but until today you have refused to review my paper from 2014. It is on you to explain what you mean with “so many of the properties”. As long as you didn’t describe them such statements are empty.
Anyway, it simply doesn’t matter how you parse the glyph groups to decide if groups are similar to each other or not. It also doesn’t matter if you cluster the manuscript as single pages, quires or by illustrations. My statement that similar words occur near to each other is true for each of this levels. See for instance Currier. He has described this pattern by splitting the manuscript into two languages A and B.
That similar words occur near to each other is a fundamental property of the Voynich manuscript. It didn’t depend on a single statistical analysis or the transcription used. By arguing that it is necessary to build statistics for each cluster of pages you already accept the idea that the texts of the manuscript is changing in some way. The only trap is to ignore this pattern and to analyze the text or some parts of the texts as uniform.
Torsten: I just wish I could get you to see clearly how the most basic things about your analyses – such as the distance between two Voynichese words – are based completely and thoroughly on a set of assumptions about what you think (without evidence or proof) is the right way to parse the raw transcription.
If I had eaten a doughnut every time that someone presented me with a post facto conclusion about Voynichese based on their unproven and untested assumptions about how Voynichese works, I’d be in a diabetic coma now.
Dear Nick,
the distance is only a way to measure the number of differences between two glyph groups. In my eyes it is obvious that ‘chol’ is more similar to ‘chor’ then to ‘chedy’. Even Currier describes observations like ‘chol’ and ‘chor’ are frequent in language A and rare in language B (see Currier 1976). There is no doubt that Curriers observations didn’t depend on something I wrote in 2014.
Anyway, if you cant accept that ‘chol’ is similar to ‘chor’ I have described this observation also for the same words (see Timm 2014 p.11 or Timm 2016 p. 3).
Sorry, but how many donuts you not eat doesn’t explain anything about what you mean with statements like “so many of the properties” or “post facto conclusions”.
Torsten: when you say “in my eyes it is obvious”, you are making assumptions about how Voynichese works. And you have neither proof nor evidence that those assumptions are valid.
And so when you draw your conclusions based on your tests based on those assumptions, you are showing not the correctness of your reasoning, but the error of your initial assumptions and the narrowness of your range of conceptions as to how Voynichese could work.
Dear Nick,
when I say that ‘chol’ is obviously more similar to ‘chor’ then to ‘chedy’ I only say that ‘chol’ is more similar to ‘chor’ then to ‘chedy’. It is a specific statement. If you want to deny this statement you should explain why you think that ‘chedy’ is more similar then ‘chor’ to ‘chol’ or why you think that it is not possible to compare ‘chol’ with ‘chor’ and ‘chedy’.
Currier wrote “The symbol groups ‘chol’ and ‘chor’ are very high in ‘A’ and often occur repeated; low in ‘B’.” (Currier 1976). In 2014 I only demonstrate that this observation of Currier follows a general rule for the Voynich manuscript. It is impossible that the observation made by Currier in 1976 is based on assumptions I have made in 2014. Therefore it doesn’t make any sense to argue that observations like that of Currier are based on errors of my initial assumptions.
Sorry, but the Voynich manuscript is what it is. Nothing you or I will write about it can change it.
Torsten: the verb ‘parse’ has two senses. I think you’re using it grammatically, where parsing a word means defining its grammatical form (so in Latin ‘amavi’ would be 1st person singular perfect indicative active of ‘amo’. So yes, you can’t parse a generated text which is not linguistic. But I think Nick is using it in the sense of identifying what constitutes a token, what constitutes a word, how many tokens make up a word – more of a compsci thing. Might this partly explain why you’re at cross purposes?
Oh, and it’s post factum, not post facto.
SirHubert: yes, I meant parse in the CompSci text-to-tokens sense. And I indeed meant post factum too, so thanks for the correction there. 🙂
Torsten: you combine observations with assumptions and expect everyone to nod.
Edit distance is not only an after-the-fact DIY statistical construction you can erect on the back of any language-like thing, it is also completely dependent on the particular way you believe Voynichese should be tokenised. If ‘or’ is a token (and I can think of plenty of good reasons that suggest that it might well be), then pretty much every one of your tables is wrong.
So how is it that your statistics, reasoning and conclusions are all so fragile, yet the strength of your belief in them is so strong?
Dear Nick,
you misunderstand the concept of similarity. It is in no way necessary to know how to tokenize a glyph group to decide if the shape of two glyph groups are similar to each other or not. If ‘or’ is a token or not doesn’t change the shape for the glyph groups ‘chol’, ‘chor’ or ‘chedy’. It also doesn’t change the observation of Currier that ‘chol’ and ‘chor’ are frequently used in language A and often occur repeated.
Moreover you use the observation that ‘or’ and ‘ol’ can replace each other in words like ‘chol’ and ‘chor’ for your conclusion that ‘or’ and ‘ol’ are used as tokens. What you describe as tokens and I describe as similar glyphs stands in the end for the same observation.
Anyway it doesn’t change the edit distance between ‘chol’ and ‘chor’ if you change a part of a glyph, a single glyph or a token of two glyphs. The edit distance is always 1 sine one element is changed.
Please explain which statistic is fragile in your eyes and why.
Torsten: you just don’t see the difference between your assumptions, your reasoning, and your conclusions.
Your assumptions include the presumption that Voynichese letters are purely letters: and also that these letters form an appropriate (and perfectly flat) set of tokens to look for edit differences between. But you have no obvious evidence for this, and certainly no proof: indeed, the whole point of the EVA transcription was to give people the chance to experiment with different ways of joining the strokes and glyphs together into tokens, because even 25 years ago there were many different theories about how to do this.
Your reasoning is derived from the various patterns of those edit distances that you have observed in your numerous statistical experiments. You’ve found plenty of interesting patterns, for sure, and for that you should be strongly commended.
And your conclusion is that the existence and arbitrary structure of these patterns only make sense if Voynichese itself is meaningless, e.g. formed by copying from some (unspecified but possibly semantic) seed text and/or by autocopying from elsewhere on the same page.
What you simply don’t seem to grasp is that all you’re doing with all this is exposing the inadequacies and shortcomings of your own initial assumptions. You’re not proving – and have never proved – that Voynichese is meaningless: instead, all you are proving is that your assumptions (upon which you based all your other tests) were wrong.
You think I’m criticising your statistics: but I’m not. I’m criticising your belief that your conclusions do anything apart from demonstrate the shortcomings of your initial assumptions, and I’m criticising your over-bullish confidence that your reasoning provides you with the only feasible explanation for Voynichese’s many curious structures. Voynichese is much more subtle than you think: and many of its subtleties seem to lie in precisely those aspects that you discarded right from the start.
I do not know how many words there are in the VM, but it is certainly several thousand.
When I look at it more closely I realize that the words are always ending but never begin with these characters. In the opposite case, the situation is similar.
With such a high number of words, one should start with a final character if it were a letter.
But still it is still trying to force these characters into an alphabet.
What I have taught to this day is that this door has more than one keyhole. But there is a system behind it.
The author of VM was not stupid surely
The match I must refrain even with the encryption of a simple system.
My opinion: The key of a number of ways.
1. Individual characters
2. Sign in combination
3. Before and suffixes
4. abbreviation (classical Latin)
5. deception
6. And finally the language, for example. Medieval Latin (vulgar / dialect)
To make matters even more difficult.
Words from the latin, italy, spain, france, portuguese, galician ………
To be able to go to.
Nick,
If Torsten chooses to count the number of instances a Voynich word appears, he need not be making any assumptions at all about how that word is compiled. The group still reads qokeedy, whether you believe that it’s made up of four tokens (qo-k-ee-dy) or seven individual tokens. It’s just recognising visually similar groups. You can argue whether it’s valid to assume that a group of characters preceded and followed by spaces does indeed constitute a word, if you really want to, but that’s a different point.
SirHubert: there are many ways in which this might not be true or complete. For example, if it were to turn out that cth was in fact a way of writing tch, then the stats for the two word patterns should be merged. Or if it turns out that there is a statistically reliable way we can use to tell whether the first letter of a line was genuine or merely prepended, that would alter things too. Or whether we could tell if -am at the end of the line was a hyphen splitting a word into two halves, then we could reconstruct split-up words into complete words. And so forth.
The bigger question is arguably about how to map between clusters (e.g. between A and B), because if basically the same language underlies both clusters, then we should be able to see from the two state machines how the two clusters express that same language despite their differences. At that point, an entirely new set of word-related statistical challenges come into play, ones quite unrelated to the sort of things that Torsten has worked on so far.
Dear Nick,
all I do is to ask what a Voynich word can stand for. You can’t blame me for not sharing your presumption that they must have some meaning. It is absurd to ask for evidence that a letter is at first place a glyph with a shape. A look in the manuscript is enough to convince yourself that the letters have shapes. The letter ‘o’ has for instance the shape of a circle and it is possible to use this letter because of its shape 😮
It is wrong that my reasoning is derived from the various patterns of those edit distances. It is possible to demonstrate the patterns by counting the numbers of times a words is used within a section, quire or page:
The word ‘chol’ is used 228 times in herbal in Currier A but only 13 times in Herbal in Currier B.
The word ‘chor’ is used 155 times in herbal in Currier A but only 6 times in herbal in Currier B.
The word ‘chedy’ is used 1 time in herbal in Currier A but 62 times in herbal in Currier B.
The word ‘shedy’ is used zero times in herbal in Currier A but 35 times in herbal in Currier B.
My conclusion is that some type of connections exists between words like ‘chol’ and ‘chor’ or ‘chedy’ and ‘shedy’. The explanation I have found for this type of pattern is that the glyph groups are autocopied. Most times the words are copied from the same place in one of the previous lines. See for instance the sequences “cthor chor daiin”, “kchor chol daiin” and “qotcho shol daiin” on page f25v (http://bit.ly/2p7D4UQ).
Sorry Nick, you can’t use your opinion as an argumentation. Even if you repeat your opinion again and again it is just an opinion. What did you expect as answer for a statement like “Voynichese is much more subtle than you think”?
Please argue with something I wrote in one of my papers instead of trying to confuse with writing about your idea of what I think.
Torsten: I strongly believe that you were led to your conclusion (i.e. that Voynichese is meaningless) as a direct consequence of your faulty assumptions about what constitutes the basic building blocks of Voynichese. Whether or not your intermediate reasoning was sound, I strongly believe your assumptions were not.
The whole point of this post was to highlight how building on flawed assumptions gives people both false results and false confidence in those results: and how this is precisely the problem that plagues Voynich statistical research. Without basic foundational research to build on (and Prescott Currier’s contribution to this is now 40 years old), all you have is a bunch of people starting from “it is obvious to me that X, Y and Z” and then doing stuff that is no help at all.
What I’m trying to do is to instead put forward a new framework for how to collaboratively tackle Voynichese (and indeed all similar cipher mysteries) to help everyone avoid these kinds of errors, particularly that of building statistical machinery on top of faulty assumptions.
Torsten: I seems to me that it is impossible to prove that Voynichese is meaningless; that of course does not mean it is not meaningless. Suppose that we have a rule that every 50th word is meaningful and all the other words are meaningless and should be ignored. Would your research pick up on that?
Nick: It seems to me that even coming up with a probability a cipher is meaningless is impossible given the infinite set of possible cipher rules. Once you have a solution to the cipher I think one would be better placed to say whether it is meaningful or if the solution is a function of chance. However even ranking possible encryption rules such that simpler rules are ranked more highly that complicated rules would be extremely difficult or impossible. I say this as one would expect a solution to be a relatively “simple” set of rules which explains all features of the manuscript. When I use the word “simple” I mean it in the sense that it is not something like “swap the 23 character with the 58 the character and so on” i.e. the rules can be described in a relatively short fashion.
Mark: until we have collectively derived some properly foundational statistical insights into Voynichese, the statistical, cryptological and linguistic analyses that get done will continue to be building on sand, never mind any supposed cipher rules that get placed on top of that. 🙁
@Mark: It is indeed impossible to prove that something is meaningless. For instance we both could agree that at someday I will you send an unreadable message and that this message mean something if it starts with the word ‘fachys’ and something else if it starts with the word ‘kchsy’. In this case the two words would mean something to you. It is also possible to use for instance the Bacon cipher to hide a message within a text (https://en.wikipedia.org/wiki/Bacon%27s_cipher). Therefore I only argue that the autocopying method was used to write the Voynich manuscript.
@Nick: My starting point was the idea that there is to much text to analyze the full text in detail. For this reason I have used a trick. I have checked only words occurring seven times like ‘oteodar’, ‘qodal,’ ‘schedy’ etc. for a pattern. Since there are only seven instances for each of this words it is possible to check each instance of them with scans of the VMS and since I have checked all instances of this words the patterns found must mean something. One pattern found was that the words are not randomly distributed within the manuscript. For instance the word ‘qodal’ occurs on four consecutive sheets and twice on page f53v. You can try it yourself just chose the number of times the words should occur …
Torsten: Maybe I am missing something, but wouldn’t you expect words not to be randomly distributed, Surely some vocabulary is much more likely to be used in some contexts rather than others. In far as we can talk about meaning that seems to be an indicator of meaning. For example astronomical vocabulary used more on the astronomical pages, recipe related vocabulary used more on the recipe pages, plant related vocabulary more common on the plant pages and so on. I am now really confused by what you are trying to demonstrate.
Torsten: I must admit I have not had time to review your research. However some of what you have done does fit with my interests though in a different way to that which you are approaching things, so maybe I should follow this up with you at some point.
Hi all,
My first comment here; please be kind.
A brief introduction – I am a molecular phylogeneticist. I take long strings of DNA sequence and analyze them statistically to infer evolutionary patterns and genetic structure. This is a process that requires extensive model-fitting using some powerful statistical approaches. The field has gone heavily Bayesian. I, myself, am more of a geneticist than a statistician, but I have a basic understanding of the process.
So, to optimize the analysis of a set of data, you need not only a model but a way to measure model-fit, so that you can optimize your model against your data.
So, how would we measure how successful a particular stroke model or parsing model would be? The only measure of “success” that I can see would be at the end, with some measure of comprehensibility. How do we parameterize stroke models or parsing models to evaluate them? How should we measure our success along the pathway?
E: to date, the way this has been approached in almost every exampled involved assuming pre-picking a model and assuming it is correct… which is specifically why I think that we haven’t got as far as we should have done over the last few decades.
To do significantly better than this, I think we have to try to collectively build up a description of those aspects of these staging post models that we think will move us forward: and then develop metrics and optimise for them.
For example: in the case of parsing Voynichese, I suspect that the right kind of metrics to be optimising for are flatness and compactness of the token state machine. That is, a good parsing model should produce a set of tokens where the outward transitions of a given token are predicted strongly by the token itself, while at the same time not producing thousands of tokens. The cases I’m particularly concerned about are to do with EVA a and EVA o (which I know have also concerned Rene Zandbergen a great deal over the years, along with the gallows), which almost always confound linguists’ attempts to interpret Voynichese as a simple language: but this is the subject of a whole blog post I’m in the process of preparing.
Example:
Let’s turn things around.
If I were to convert these Latin words to VM using the EVA system, all words would look the same.
a ex a
a que
a qu a
a qua
aqua
a exi
If I want to reverse the way, it will not work.
So I’m not a friend of EVA
Dear all, I urge the membership to take a peek at the language Khudabadi where Wiki has a useful chart showing 58 glyphs for this phonetic syllable- based (abugida) language. It was used by the Sindh people of Northern India who had recently been displaced by discrimination from their homeland mainly by Muslim conquest but also some of their customs, drinking wine, drinking hemp seed mixed with water (“bhat”),, emancipation of women and others.
The language uses a lot of diacriticals, many of them similar to those discussed by Nick in Curse, p. 168. For example we find m, m with a macron-like scribal flourish, m with an even longer flourish. These are the vowels: a, e, and o, respectively. m with no flourish at the start is “tha”. The glyph “n” with a flourish at the front is “ka”; with a flourish at the tail= “ma”. This language was created shortly after the move to write home and I am guessing was deliberately cryptic. This language would have been tricky to use as so many of the glyphs resemble one another, as also seen with the VM. There are four variations on the “tipped 2”. There are also four “c-like” glyphs, a c with the upper part of the curve extended (= i ); “c-c” linked at the top (=sa ); a linked c’s with an extension top of the right-most c; (=ii) a “c” with an extension to the back of the upper curve of “c” (=tta”
The Khudabadi language is based on Landa as was Kojki, that Sukhawant Singh proposed in Nick’s blog site on April 29, 2014 and that I referenced in my post to Nick’s site on Feb. 8, 2017. I liked it then but I think Khudabadi is a better fit with the VM text. Both, like, Sanscrit,, are read L->R.
My absence from posting anything since March 9 is due to the exigencies of assisting in the writing of a paper on defensive secretions of Tasmanian millipedes.
Anyway, to return to “Curse”; I think Nick was right on the money with his focus on those scribal flourishes over the “m’ like glyph. Cheers, Tom
Dear all, A followup to my above post deals with the time line of when the Khudabadi language was created. Google books has picked up a monograph by Divendra Naran written in 2007 entitled “Research in Sociology-Concept Publication” where he states on pp 105-106 that the migration of these “oppressed” people occurred in the 13thC although other sources indicate the 15thC. Key sources appear evidently to be written in Khudabadi that defies any translation by my software.
One source indicated that Khudabadi grew out of languages used by the Lohana caste (scribes and accountants), who also used Khojiki. It should be pointed out that Sindhis originally used eight different scripts of which Khojiki and Khudabadi were two. Another source indicated Khudabadi was created ca. 1351. It became known as “Vaniki” that meant “trader”. The capital of this Sindh population was Khudabad which meant “City of God”and this part of the Sindh diaspora is in what is now southern Pakistan (Dadu district) and borders Baluchistan,
Other glyphs that appear in Kudabadi are “o”, “w”, a Greek gamma-like glyph that is “ca” and an Arabic “7” (=pa). It should be stressed that Khojiki has a number of “gallows” like glyphs, e.g. one is the mirror image of double stemmed, single looped gallows (= ba ). One possibility is that the VM has glyphs from both Khojiki and Khudabadi languages. Cheers, Tom
Dear all, Rather than get into the weeds with linguistic punctillios, I would like to make an argument as to what I consider the likely venue for the enscription of the VM.
I think it is INDIA, starting with herbs and spices from the SW coast, known more familiarly as “The Malabar coast”. Supporting this view are the following arguments.
1) In the herbal section, I think that Yin/Yang symbology is shown by the brown/orange color representing the female (yin) principle; blue representing the male (yang) principle. Furthermore, leaf shapes and directionality (e.g. f46r; all to the right or all to the left (could be yin or yang respectively or the reverse depending on the particular source). That fern (f38r) has yang-like symbols and its use thus suggests it is for males. India claims to have first formulated the equivalent of Yin/Yang philosophy, which then spread further to the East.
2. The illustrated page (VM f86v3) I have alluded to previously shows, I believe, the obtaining of diamonds from steep, snake-infested ravines in the East central region of India. Marco Polo writes in detail about the use of birds diving to retrieve thrown in moistened meat that emerge in the beaks of these birds with the diamonds affixed. I think that this is the only depiction of birds in the entirety of the VM.
3. The strong resemblance of parts of the VM text to one of the Brahmic languages, in particular languages created in the 14th C based on Landa such as Khudabadi discussed above.
I still hold to the belief that some Armenian does appear in the VM, particularly the 89 numbers that I have argued refer, when Romanized, to the letters “et” used in Latin for “and” or parts of words like “set”. The ampersand (&) and the glyph resembling “&” used in cursive Armenian as “f”.
If the Sindh language that I think comprises the bulk of the VM text and was used by traders, accountants or scribes, I think it reasonable that these folks would have encountered Armenians who were always active in trade.
I plan to push northwards through Sindhi provinces to the Hindu-Kush mountains where the female imagery makes more sense that postulating excessive iconography. The Hindu-Kush, then under the Moslem yoke, was a “Hindu killer”as that name implies.
To get the flavor of this region of India, I suggest a read of Kipling’s “The Man Who Would be King”, available as a pdf on Google and a short story that many critics claim to the one of the finest ever written. It was made into a film starring Connery, Caine and Christopher Plummer (as Rudyard Kipling)..
My view at the moment is that the VM could be a common place book or a travelogue, sort of “In the Steps of Marco Polo”.
Will write more soon on the Chitral valley of the Hindu-Kush where hot mineral springs exist,, boasting even shortish crocodiles. Marco Polo passed through but evidently missed the crocs. Cheers, Tom
Nick, in one of your comments above you say, “For example: I have a substantial set of reasoning that suggests that what is transcribed as ckh and cth should instead be parsed as kch and tch, which would change a lot of statistics.” Using that as a springboard to a broader point, any discussion regarding issues like this need to reflect an awareness of/be informed by/respond to Currier’s logic with respect to issues like “4. The Nature of the Symbols cTh, cKh, cPh, cFh” is his seminal paper (http://www.voynich.nu/extra/curr_main.html). (Your reasoning on the issue may well do this; I just wanted to make the point…) — Karl
Karl: rest assured that I don’t do anything without checking Currier first. 🙂