A little bird (hi, Terri) told me about a flurry of activity on the Voynich mailing list prompted by some posting by Sean Palmer, who Cipher Mysteries readers may remember from his pages on Michitonese and the month names. Well, this time round he’s gone after a rather more ambitious target – the internal word structure of Voynichese.
Loosely building on Jorge Stolfi’s work on Voynichese word paradigms, Sean proposes a broadly inclusive Voynichese word generator:-
^ <---- i.e. start of a word (q | y | [ktfp])* <---- i.e. one or more instances of this group (C | T | D | A | O)* <---- i.e. one or more instances of this group (y | m | g)? <---- i.e. 0 or 1 instances of this group $ <---- i.e. end of a word
...where...
C = [cs][ktfp]*h*e* <---- i.e. basically (ch | sh | c-gallows-h) followed by 0 or more e's T = [ktfp]+e* <---- i.e. gallows character followed by 0 or more e's D = [dslr] <---- i.e. (d | s | l | r) A = ai*n* <---- i.e. basically (a | an | ain | aiin | aiiin) O = o
Sean says that his word paradigm accounts for 95% (later 97%) of Voynichese words, but I’d say that (just as Philip Neal points out in his reply) this is because it generates way too many words: what it gains in coverage, it loses in tightness (and more on this below).
Philip Neal’s own Voynichese word generator looks something like this:-
^ (d | k | l | p | r | s | t)? (o | a)? (l | r)? (f | k | p | t)? (sh | ch )? (e | ee | eee | eeee)? (d | cfh | ckh | cph | cth)? (a | o) ? (m | n | l | in | iin | iiin)? (y)? $
Though this is *much* tighter than Sean’s, it still fails to nail the tail to the sail (I just made that up). By 2003, I’d convinced myself that the flavour of Voynichese wasn’t ever going to be satisfactorily captured by any sequential generator, so I tried defining an experimental Markov state-machine to give an ultra-tight word generator:-
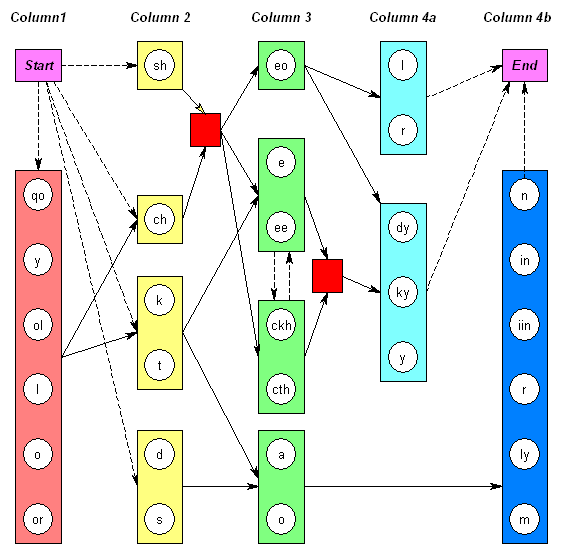
It wasn’t by any means perfect (there’s no p and f characters, for a start), but it was the kind of thing I’d expect a “properly tight” word paradigm to look like. But even this proved unsatisfactory, because that was about the time when I started seeing o / a / y as multivalent, by which I mean “performing different roles in different contexts”. Specifically:-
- Is the ‘o’ in ‘qo’ the same as the ‘o’ in ‘ol’ or ‘or’?
- Is the ‘a’ in ‘aiin’ the same as the ‘a’ in ‘al’ or the ‘a’ in ‘ar’?
- Is word-initial ‘y’ the same as word-terminal ‘y’?
Personally, I think the answer to all three of these questions is an emphatic ‘no’: and so for me it was the shortest of ceonceptual hops from there to seeing these as elements of a verbose cipher. Even if you disagree with me about the presence of verbose cipher in the system, I think satisfactorily accounting for o / a / y remains a problem for all proposed cipher systems, as these appear to be knitted-in to the overwhelming majority of glyph-level adjacency rules / structures.
Really, the test of a good word generator is not raw dictionary coverage but instance coverage (“tightness”), by which I mean “what percentage of a given paradigm’s generated words does the instances-as-observed make up”.
Philip’s paradigm generates (8 x 3 x 3 x 5 x 3 x 5 6 x 3 x 7 x 2) = 1,360,800 possible words, while my four-column generator produces – errrrm – no more than 1192 (I think, please correct me if I’m wrong): by contrast, Sean’s generator is essentially infinite. OK, it’s true that each of the three is optimized around different ideas, so it’s probably not entirely fair to compare them like this. All the same (and particularly when you look at Currier A / B sections, labels, etc), I think that tightness will always be more revealing than coverage. And you can quote me on that! 😉
What happened to Stolfi? His work is mentioned so often, I wonder whether he is still following the Voynich discussions.
Oh yes, and why can’t we all use Voyn-101? Isn’t EVA recognised as being inferior? I still haven’t got the hang of mentally converting “qokeedy” into Voyn-101.
Julian: As far as I know, Stolfi just got too busy with other stuff to fit Voynich studies in as well – one day he’ll come back to the fold. 🙂
Voyn-101 has different problems, neither it nor EVA has Voynichese mapped out 100%. The biggest problem both systems arises from those adherents who take them too literally – for example, people who treat EVA ‘h’ as a real letter worthy of statistical or linguistic analysis. Oh, well!
(i.e. in both cases, you almost always need to pre-filter the data to fit your own particular transcription model before doing tests on it.)
Maybe this has been mentioned in the mailing list, but what you refer to as tightness and coverage, is called precision and recall in the grammar induction literature.
In this case precision would be the number of generated Voynich words divided by the total number of generated words, whereas recall would be the number of generated Voynich words divided by the total number of Voynich words. It is always possible get perfect recall by simply generating all sequences of all letters with a very compact generator. People tend to take the harmonic mean of these two values (the f-score) as a reasonable indicator of how good a generator is.
One problem here is that we don’t have the set of all legal Voynich words, and we don’t really know how large that set is, so it’s difficult to find the recall exactly. The generator might be generalizing perfectly and generating lots of legal Voynich words that simply aren’t in the manuscript, and we’d have no way of knowing.
Another problem is that to say anything meaningful about these generators we should compare them to generators for similar sequences of tokens. We can’t really say what it means that such a small generator gets f-score X unless we know that (for instance) English words require a vastly more complex generator to get that kind of f-score.
One way to solve this would be to run a grammar induction algorithm on Voynichese and natural languages and compare the complexity of the generated grammars. If such an algorithm finds significantly smaller generators for Voynichese, then that’s an indication (though not proof) that Voynichese has a more regular word structure.
I actually tried this a while back with a relatively simple algorithm but results were very much inconclusive.
Peter: thanks very much for this – I’m surprised (at myself) that I haven’t yet reviewed your 2006 paper on applying ADIOS to the VMs, it’s certainly something I’ve been meaning to do. All the same, the short version would read: “I strongly suspect that you would need to apply some kind of pre-parsing to the Voynichese corpus in order to give the ADIOS algorithm any real chance of producing anything revealing.” Would you be interested in trying this?
I’ve been meaning to revisit that paper (actually my BSc thesis) for a long time now. Before you spend to much time with it you should know that my interpretation/implementation of the algorithm was flawed. I fixed it for a later project, see here (not related to the VMs, but a nicer paper). It would take some time to get the code going again, but it’s worth a shot.
I sort of gave up on it because I found that ADIOS relies strongly on knowing where the sentence boundaries are. Of course, on the word level, this is no problem…
I would be very interested in hearing about pre-parsing strategies. I’ve always been a little too lazy to to get too deep into the specifics of transcription and just used whatever EVA transcription seemed reasonable for quick experiments.
Peter: I’ve spent years trying to work out how Voynichese should be pre-parsed, because I think this runs right to the heart of its cryptological challenge.
The first parsing level is that EVA was deliberately designed to be a stroke-based transcription, so there’s a high probability that ch / sh / ckh / cth / cph / cfh / eeee / eee / ee all represent individual glyphs (the Voy-101 transcription transcribes all these as individual glyphs for this reason).
The second parsing level is that I think we’re looking at a verbosely enciphered scribal shorthand (where the brevity gained from the contraction & abbreviation is cancelled out by the verbose expansion) based around o/a/y, and hence groups like qo / ok / ot / op / of / ockh / octh / ocph / ocfh / ol / or / om / al / ar / air / aiir / aiiir / an / ain / aiin / aiiin / am / yk / yt / yp / yf / yckh / ycth / ycph / ycfh / eo all encipher individual tokens (but be sure to parse qo first, as ‘qok’ = ‘qo’ + ‘k’, not ‘q’ + ‘ok’). Just so you know, my prediction is that ‘d’ codes for a ‘contraction’ token, ‘-y’ for an ‘abbreviation’ token, and a[i][i][i]n for Arabic digits (in some way), while ‘l-‘ in Currier B is an optional equivalent to ‘ol-‘ in Currier A.
The third parsing level is that, apparently because ol / or / al / ar often appear next to each other, the encipherer occasionally inserts a space inside the pairs, apparently to break up the visual pattern. Hence I suspect that any occurrences of o.l / o.r / a.l / a.r should first be reduced to ol / or / al / ar in order to undo this transform.
Hence, what I’m suggesting is that it is the pervasiveness of the o/a/y groups that causes automatic rule finders (and similar Markov state machine inference engines) to find no obvious word structure: so if you pre-parse these out, I’m pretty sure that a whole deeper level of word structure will present itself.
Hope this is a help!
Hello Nick,
A small point (which has been covered somewhat before), but wouldn’t one way to “tighten up” the word model, is to try and de-conflict the symbols that could never fit the model (ie resolve the “end of line” dependent symbols into plausible existing symbols).
Eva “g” occurs about 96 times, of which around 65 are end of lines, thus it has a manufactured feel to it verses being part of a word structure…my guess is it’s just a “d” with a tail the author added.
Eva “m” occurs about 1196 times, of which about 820 are end of lines. This symbol seems to behave the same as “g”, and therefore may be a flourished version of an existing symbol (my guess “i’).
Although a small impact overall, they just don’t seem to fit the word models given their end of line dependence. If you accept the above, the question now is why would the author do this…of which an answer may lie in your comment on “multivalent” symbols, which I also believe is key to the VM structure/cipher.
BTW : 67% of g’s are end of lines
68% of m’s are end of lines
….strange co-incidence indeed.
TT
Tim: a proper word model would also need to ignore the first letter of a page (or indeed paragraph, or indeed line), as well as the last one or two characters (particularly if am), as well as Philip Neal’s key-like features (which are prototypically bound by a pair of f or p gallows, about 2/3rds of the way along the top line of a page or paragraph). Philip has pointed this out for years, and I completely agree.
However, perhaps the most useful feature of a properly ‘tight’ (or, as Peter Bloem prefers, ‘precise’) word generator would be to quickly direct our attention to those places where the model does not apply. These should be hugely informative, as they perhaps point to breaks in the system caused by awkward content in the plaintext – possibly proper names, numbers, etc.
In fact, it may well be that we should be trying to create a two-track generator – an extremely precise generator [in green] and a reasonably precise generator [in amber] – and using these to automatically markup a transcription [with anything that doesn’t fit in red]. Just a thought!
If the VM is composed using an aleatoric game, then you’d expect the words which cannot be generated by (our reconstruction of) the game to be scribal errors or boredom. Examination of the non-covered words would give insight there as well.
It might also be worth comparing to the codex seraphinianus as an example of a text “made up to look good” without any rules meaning. It would thus be useful as a control, along with Latin, English, and various secret languages or contemporary codes.
Scott: oooh, I don’t know about that. Trying to classify Johannes Ockeghem’s 15th century multi-modal music “aleatoric” would be stretching the term beyond breaking point: aleatoric artistic work don’t seem to me to have any obvious history pre-1900, which is one of the key reasons why Gordon Rugg’s pseudo-random Cardan grille daemon is so much of a stretch as a way of generating the VMs. This was in an era without 20-sided dice (though the Romans apparently had some, if this one is not an Egyptian fake), so we should see some pretty obvious statistics emerge from any aleatoric process, right?
Also, I’m still far from convinced that the Codex Seraphinianus’s text was constructed solely to look good – there’s a core of deliberately warped hyperrationality to that, whatever Serafini may now (belatedly) claim – and so I’m not sure that all the parallels with that will turn out to be as revealing as you hope. Oh well!
Hi
Sorry, I am confused by this graph.
There are dashed and continuous arrows, does that mean different things?
Am I correct that a box with circle inside means that any of the sequences in the circles can be emitted when the machine enters the squared box? Can a squared box emit nothing?
What is the meaning of red boxes?
“Markov” states machines are tied to probabilities, but I do not see any here.
Thanks a lot in Advance for clarifying.
Regards
Maxi
Maxi: sorry, I wrote this post 11 years ago about a state machine I put together at least five years before that. I will have to dig into my archives to work out what was going on there…
Thanks Nick, I think I posted the same message twice, apologies. Looking forward to hear about that (spoiler alert: I am also having fun with state machines :-)).
And happy to know if you know of other models except those you mention above (I know of the Curve-Line system from B.Cham and the grammar from E.Vogt (only for Currier B if I am not mistaken).
Hi. I just want to mention I just published a piece where I describe my own grammar and I show how it performs better than other known to me in terms of “tightness” vs. “coverage” (as measured by F1 score).
If anybody is interested, the link is here:
https://mzattera.github.io/v4j/008/
Maxi: hey, this is really neat stuff, thanks for sharing! 🙂
I am (of course) pleased that it turned out that my model was the one yours had to beat, even if I didn’t build it as precisely as you would like. 😉
Naturally, I’ll have to come up with a new model, now that there’s a bit of sport involved. But it’s going to take me a bit of time to understand what your model did right, it’s certainly not obvious from the state transitions. :-/
@Maxi.
I just read your Github summary. It is very impressive in its simplicity. There is one topic that I have been thinking of for a long time, but I could not start with. It is related to automatically identifying the structure of Voynich texts. Based on your works published on the Github, I think you might get interested in what I have on my mind. If you are interested, could you email me your contact to [email protected]? Then I will explain it to you in details.
Hi Nick, thanks : ) Happy I stirred some interest.
The grammar was waiting on my desk for too long, so I finally decided to push it out as soon as I had some time, but I want to add some more pictographic descriptions to capture what the model does. If you have access to Gephi, playing with the graph iteratively helps a lot to understand the model.
I think the key is it starts from the “slots” concept, which itself is a decent model of word structure (I believe).
Last but not least, I hope all of my computations are correct. As I wrote, I was not able to reconstruct the workings of your state machine fully and had to go for some assumptions. As usual, if anybody spots an error I’d be happy to correct it, the code is public.
Nick, A reader who evidently thinks (poor chap) that I might have something useful to say about ciphers and Voynichese has asked what I think about “new discussion of Markov chains”.
No idea what the “new discussion” might be, but I suggested he search your site – then did the same, and found this fascinating post.
I understand that Markov chains might help crack a cipher. Not sure a cipher constructed no later than 1440 could have used such principles. Any thoughts on that?
D.N.O’Donovan: Markov chains can be useful analytical tools in understanding countless linguistic behaviours, as well as cipher behaviours. The properly smarty-pants stuff is HMM (“Hidden Markov Model”), which tries to infer unseen states from the way a text corpus works. As I recall, Mary D’Imperio was into HMMs, so I’m not sure how “new” the discussion really is. 😉