Once upon a time (as most Voynich research stories begin) around 2003, there was a brief fad amongst VMs mailing list members for constructing Markov (state-based) models for Voynichese. My own (in retrospect not so good) contribution looked like this: incidentally, this is hosted as part of a “non-systematic miscellany of Voynich-related documents, scans, diagrams and images” here on my personal pages.
{kind=link}
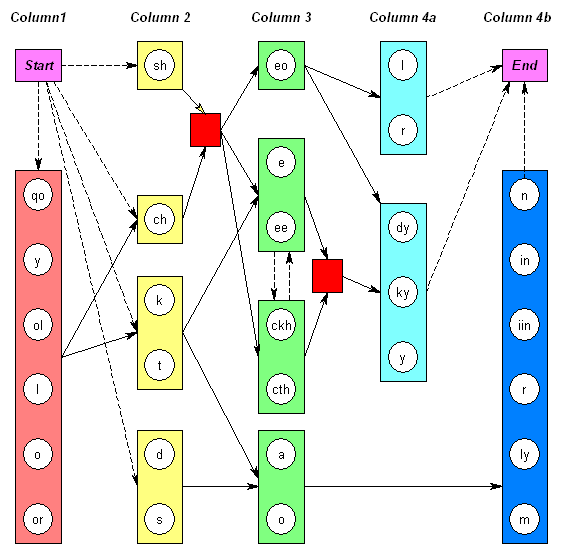
I’m currently thinking about revisiting this whole Markov model thing, but using tokenised adjacency tables to help construct it. That is, first tokenise the selected text (Currier A pages, Currier B pages, labels, etc) according to a set of predetermined frequent (possibly verbose cipher) pairs (such as ol, or, al, ar, am, aiiii, aiii, aii, ai, qo, etc), then build up a large “adjacency table” (i.e. counting the occurrence of adjacent tokens in a 2d grid, first token indexed up the left, second token across the top).
It might be said that the whole point of constructing Markov models is to work out what the tokens are. To which I would reply that trying to work out both word structure and token structure within the same model has to date proved unhelpful. In fact, I think the overloaded way that “a” and “o” are used within Voynichese (for example, the “o” in “qo” is unlikely to be the same kind of “o” in “ol”) may well be a sign that these were deliberately designed to confuse decipherers as to the structure of the tokens, in a tricky Quattrocento Sforza cipher sort of way.
Or, in terms of signal processing, I’d say that the verbose cipher convolves the text signal, blurring away most of the sharp boundaries in the underlying plaintext you’re hoping to model.
The new twist I have on all this is to exclude a lot of noise when collecting the adjacency stats, in particular the first tokens of each line. This thought came from a recent email exchange with Marke Fincher, who reminded me that the first letter of each line is often unreliable, and in particular…
Check out lines which include the EVA-strings “YSHEO” and “YCHEO”.
These strings are almost always line-initial, and probably because the Y is in fact data from a vertical column of symbols.
Ditto for “dche” I think.
(By the way, I think “eo” occurs twice as often in A pages than B pages.)
Thinking about line-initial letters, if you take a random page from the VMs (say, f77r) and look at the first column of tokens (I used Takeshi Takahashi’s VMs transcription for the following), you’ll see that its elements typically come from a very limited group: the “s qo s qo s qo” sequence near the start could be deliberate padding, rather than just coincidence or a coded reference to an early line-up of Catford’s finest band “Status Quo” (as I suspect Francis Rossi was born post-Renaissance):-
p t qo s qo s qo s qo d qo qo che qo sheo d ot qo s ol s qo qo q d qo s d t p ol d d qo d shee qo d y s
Yet if you look at the form of the “s” characters when written as the first character of the line (which occurs more in B pages than in A pages, I think) as appear on the page, you can see various subtle scribal forms of it appearing: “round head s”, “flat head s”, “short s”, “long s”, etc. Might these be a kind of steganographic anti-transcription cipher? It’s certainly a thought..