Back in 2006, I argued (in ‘Curse’, pp.58-61) that a series of seven consecutive circular diagrams in the Voynich Manuscript’s Q9 (‘Quire 9’) and Q10 probably represented the seven ‘planets’ of traditional astrology / astronomy.

(Note that the wide Q9 bifolio had been incorrectly rebound at some point in the manuscript’s history, making this sequence far from visually obvious). My argument relied on these observations:
- The page immediately preceding the set contains a rotated / inverted T-O map (representing the Earth) surrounded by a wolkenband (representing the heavens). Note: we now also know that this strongly parallels a drawing in a high-quality presentation manuscript by Nicolas Oresme.
- The pages immediately following the set contain a series of zodiac roundels (that we now know seem to have been copied from a 1420s Alsace calendar).
- The zodiac roundels also seem to be related to Vat Gr 1291, a copy of Ptolemy’s Handy Tables, which I blogged about here.
- One of the pages in the set contains a sun roundel (f68v1)
- Another of the pages contains a large moon roundel (f67r1)
- One of the pages has a 46-way radial symmetry, which eerily coincides with Mercury’s Babylonian 46-year goal year period. (Saturn has a 59-year period, Jupiter a 71-year period, Mars a 79-year period, while the octaeteris was where 8 Earth years correspond to 13 Venus years). It’s not proof that the roundel on f69r is linked to Mercury, but it’s a good start.
But now it’s 2020, and I’m wondering if I can now take this argument up to the next level. This is because some medieval / early modern astronomical manuscripts also contain a series of large circular diagrams corresponding to the seven classical planets. These are known as Theorica Planetarum manuscripts, and their circular diagrams are paper machines – that is, they are rotating volvelles duplicating the Ptolemaic epicycles long used by astronomers and astrologers to approximate the movements of the planets.
Hence the Theorica Planetarum Voynich Manuscript hypothesis is simply the suggestions that the set of seven consecutive circular diagrams in the Voynich Manuscript’s Q9 and Q10 might actually be (in some way) standing in for the circular paper machines in Theorica Planetarum manuscripts.
But to follow this research thread through to its logical end, we will need to know a lot more not only about Theorica Planetarum manuscripts (and their diffusion through Europe), but also about Ptolemaic epicycles, which is what the Theorica Planetarum models were trying to emulate.
Epicycles
In the pre-Copernican time period we’re interested in, the dominant belief (because all the rest was heresy) was that the celestial spheres rotated around the Earth in a perfectly circular manner. Bede’s De Natura Rerum depicted it thus:
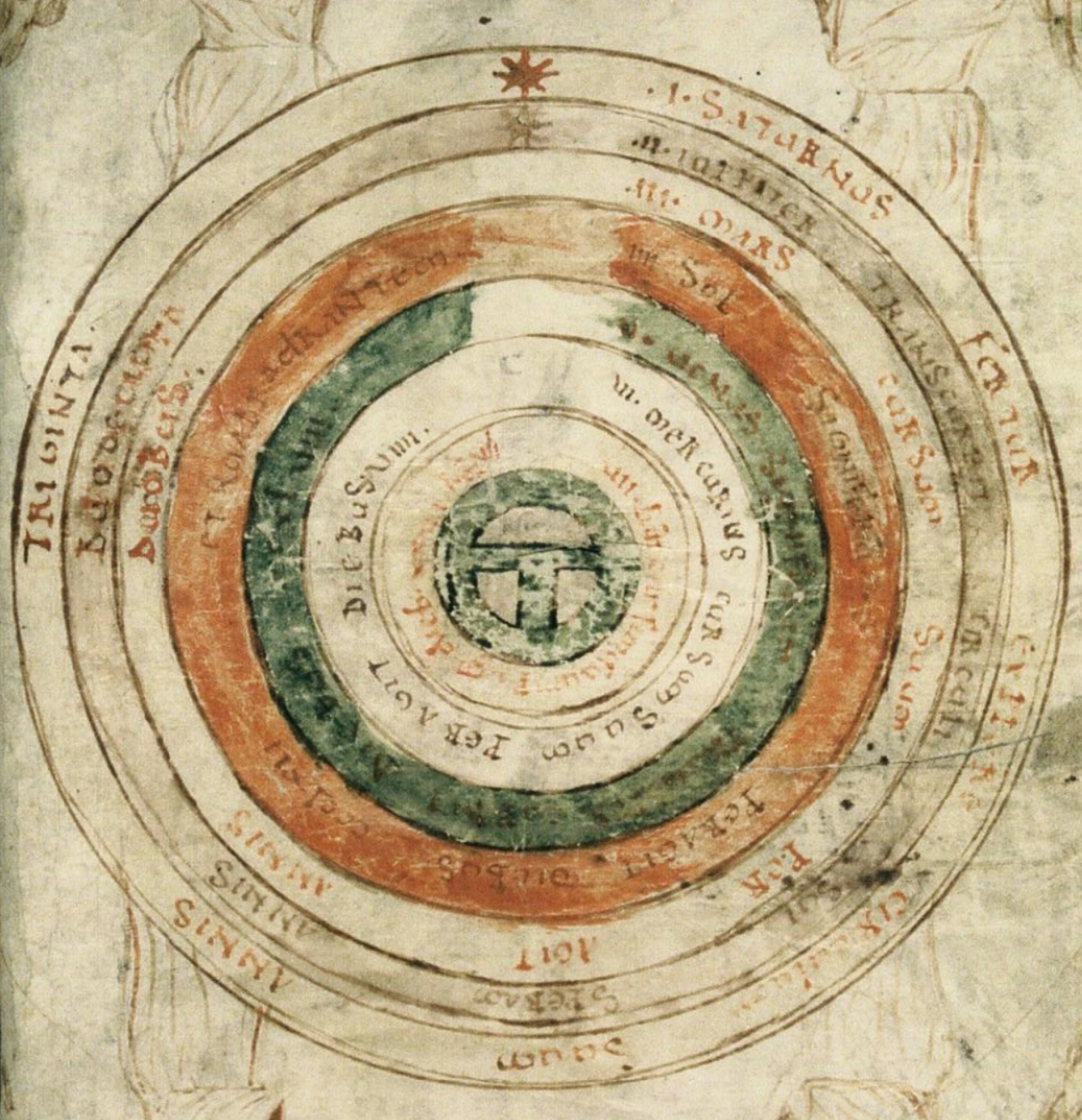
Unfortunately, if you were an astronomer and tried to use this model to predict the movements of the wandering ‘planets’ (which back then included the sun and the moon), you’d be quickly disappointed. Because it doesn’t work. Not even close.
The most obvious thing that goes wrong is that planets often appear to be travelling backwards relative to how you would expect to see them move if they were rotating around simply (this is known as ‘retrograde motion’).
To fix this, the Greeks (specifically Hipparchus and Ptolemy) came up with a mathematical trick that instead modelled a planet’s movement as a smaller circle (an “epicycle”) attached to (i.e. offsetting from) a larger circle (a “deferent”). While not perfect, this was a step in the right direction.
Mathematically, you can think of epicycles as a kind of two-term Fourier approximation of a more complex function. And this trick was what astronomers and astrologers were still using more than a millennium later.
Oh, and there was a further trick: even if your epicycles are able to account for retrograde motion, the velocities of the planetary motion were still variable. And so Ptolemy added the idea of the equant, based on observations made by Theon (probably Theon of Smyrna), which offset the (virtual) place of observation to account for variable velocities.
Mathematically, this was a secondary kludge with no basis in anything anyone could point to as an actual reason. In fact, the whole idea of the equant annoyed Copernicus so much that it has been argued he came up with his whole heliocentric system simply to throw equants away.
All the same, the combination of Ptolemy’s equant and a deferent/epicycle per-planet pair proved to be a practical enough solution to the problem of predicting planetary motion, regardless of what Copernicus thought. 😉
Note that some (old-fashioned) astronomy historians asserted that more and more epicycles were added over the centuries to try to make the models better approximate the reality, but this is a myth. It’s true that Copernicus added an extra epicycle per planet, but this was because he was trying to get rid of that pesky equant. The two were essentially the same.
Clockwork Cosmoses
Putting the equant to one side, the epicycle/deferent values reduce to a discussion of ratios:
- What is the ratio between the deferent period and the solar year?
- What is the ratio between the deferent period and the epicycle period?
- What is the ratio between the deferent radius and the epicycle radius?
If you know these values, not only can you calculate tables of planetary positions, but you can also build physical models – both volvelles and clockwork mechanisms.
Famously, the (pre-Ptolemy) Antikythera Mechanism used tricky gearing to model the moon’s anomalous movements. Incidentally, Freeth and Jones (2012) proposed an interesting reconstruction of the rest of the planetary movements in the AK by ‘scaling up’ its tricky lunar gearing.
However, because all other Greco-Roman models are lost to history (despite mentions in Cicero, no extant artefacts are known), we now have to fast-forward to the 14th century, and the Ptolemaic clockwork cosmos of Giovanni Dondi. His astrarium was much seen, described and admired, and in 1381 he gave it to Gian Galeazzo Visconti: it stayed in Pavia till at least 1485. (It seems likely that Leonardo da Vinci saw it). There are a number of modern reconstructions, such as this one which I once saw in Milan:

Helpfully, Giovanni Dondi described his astrarium’s inner workings in his Tractatus astrarii (Padova, Biblioteca Capitolare, Ms. D.39 and one other were by Dondi, but at least ten other manuscript copies exist). There’s a critical edition: Giovanni Dondi dall’ Orologio, Emmanuel Poulle (ed., trans.) (1987–1988) Johannis de Dondis Padovani Civis Astrarium. 2 vols. Opera omnia Jacobi et Johannis de Dondis. [Padova]: Ed. 1+1; Paris: Les Belles Lettres.

From this, we know that Dondi designed his astrarium to function according to the 13th century Theorica planetarum of Campanus of Novara (more on him later) and the Alfonsine tables (circa 1272).
Might the Voynich Manuscript’s seven planet pages be not astronomical but simply a copy of the relevant pages of Dondi’s Tractatus astrarii? It’s very possible, but let’s not sink into the murky world of theories just yet. 😉
Theorica Planetarum Gerardi
Olaf Pedersen’s 1981 paper “The Origins of the ‘Theorica Planetarum” notes that the Theorica Planetarum specifically described the motions of the planets: and was much copied because other texts like the Sphaera of Sacrobosco were quite lacking in that respect.
The incipit was “Circulus eccentricus vel egresse cuspidis vel egredientis centri dicitur qui non habet centum suum cum centro mundi“: and Pedersen reports (in 1981) having more than 210 entries on his checklist of copies, which makes it almost as widely circulated as Sacrobosco’s Sphaera.
As to its author, it was widely believed to have been written by Gerard of Cremona (hence you’ll often see it referred to as Theorica Planetarum Gerardi). Regiomontanus called it by this name, though he was aware there was no proof that Gerard had written it – and by Regiomontanus’ time, it had become known as Theorica Planetarum Antiqua.
Pedersen himself came to no conclusion about who actually wrote this, but considered that he knew of nothing that “[invalidated] the assumption that it originated from the hand of a thirteenth-century author”. (p.122)
Campanus of Novara’s Theorica Planetarum
The next Theorica Planetarum to take the medieval stage was by Campanus of Novara (c.1220-1296), and was composed (1261-1264) at broadly the same time as the Theorica Planetarum Gerardi.
This was a very much more solid affair (without a number of the erroneous simplications the other Theorica had included), and included a description of how to make an equatorium. This is essentially a single mater (an astrolabe-like back disk), into which other disk-sets are inserted, one disk-set per planet. This would be cumbersome and impractical, though the equatorium article linked here says: “[I]t is however likely that Campanus envisaged an instrument of gigantic dimensions.”
There’s a critical edition of Campanus’ Theorica Planetarum by Benjamin and Toomer, which I’ve ordered a copy of from America (though I don’t expect it to come anytime soon).
There was also a tidied-up version of Campanus’ work from circa 1320, called “Abbreviatio instrumenti Campani, sive aequatorium” by Johannes de Lineriis (Jean de Linières or Lignières). I’m guessing that Benjamin and Toomer’s book covers this (but I’ll find out when it arrives).
Georg von Peurbach’s Theoricae Novae Planetarum
In many ways, Georg von Peurbach’s much-updated Theoricae Novae Planetarum (1454) was the last hurrah of the Theorica Planetarum genre. Regiomontanus (von Peurbach’s student) even went to immense expense to print his late teacher/mentor’s work in 1472.
Michela Malpangotto’s (2012) article “The Early Manuscripts of Georg von Peuerbach’s Theoricae Novae Planetarum” lists five very interesting early copies of the manuscript, dating from 1454 to the early 1460s:
- “A” = Vienne, Österreichische Nationalbibliothek, Cod. 5203
- “B” = Vienne, Österreichische Nationalbibliothek, Cod. 5245
- “C” = Heiligenkreuz, Stiftbibliothek, Codex Sancrucensis 302
- “D” = Cracovie, Bibliothèque Jagellonne, B. J. 599
- “R” = Rimini, Biblioteca Civica Gambalunga, Sc-MS. 27
Here, there are particularly strong relationships between the A/B/C copies, that make it look as though all three were created in 1454 in Vienna.
What About Gotha Chart. A 472?
I discussed this manuscript in my previous post, and I’m sorry to say that I don’t as yet know how this – and by implication the whole Profatius Judaeus thing – fits into the Theorica Planetarum landscape.
Volvelles or Equatorium Inserts?
So here’s one of the many problems to clear up. Campanus’ Theorica Planetarum describes an equatorium, i.e. a series of multi-layer circular inserts that slot into an astrolabe-like mater… not volvelles.
Moreover, even though Georg von Peurbach’s Theoricae Novae Planetarum was printed as volvelles in the 16th century (e.g. the LJS 64 copy I showed the video of before), I’m entirely unsure whether the transition to volvelles there was by Regiomontanus (Regiomontanus certainly had volvelles in his 1474 Calendar) or a later thing.
So, without reading a ton more stuff, I’m entirely unsure whether volvelles (as volvelles, not as equatorium inserts) were found in the Theorica Planetarum genre at all pre-1500.
But these are early days. I’ll blog more as things become clearer. 🙂














































{kind=link}