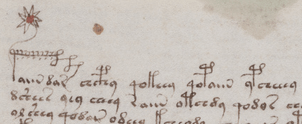I thought it would be a good idea to post up as many of the different research threads relating to Quire 20’s (‘Q20’) original bifolio nesting / ordering in a single place as I could. However, be warned that there are… quite a lot of them.
Ornate Gallows
There is only a single ornate (swirly) gallows in Quire 20. Yet oddly, it’s to be found not at the start of the quire (as you might expect), but instead at the top of f105r (i.e. the front of the third folio in):
So, if your basic assumption about Q20 is that its bifolios are in the correct order, then it would seem that this ornate gallows poses you a problem: it ‘feels’ like it’s in the wrong place.
However, as we’ll see, there are plenty of other types of evidence we can look at, and – annoyingly, but probably unsurprisingly – they all yield a slightly different spin on the same basic question of ordering.
Wladimir’s Wormholes
In a very interesting recent post, Wladimir Dulov noted various patterns of wormholes on Q20, particularly on f114, f115 and f116. One cluster of wormholes starts large on f116 (the end page), becomes slightly smaller on f115, and smaller still on f114: this seems to imply that these were made when the bifolios were in their current (final) nesting order.
As an aside, book-worms are actually woodworms, and so don’t – as Rene Zandbergen has pointed out – like eating vellum. Wormholes in vellum typically mean that the book had had a wooden cover which the worms had eaten through first, before carrying on munching into the vellum (then stopping after a couple of pages).
Incidentally, I’ve long suspected (from the curious quire numbering style and the careful vellum repairs) that the Voynich Manuscript may well have spent time in a Swiss monastery library (and, I’ve argued, probably not too far from Lake Constance): and my guess is that this was probably where it had a wooden cover added. (Perhaps even in a chained library [“Kettenbibliothek”] such as Schaffhausen.)
So far, so wormy. But Wladimir’s nice point is that there is also a second set of wormholes on f114 and f115, which doesn’t go through to f116. In fact, f114 and f115 have an abundance of wormholes (not just the ones Wladimir mentions) not visible on f116, or indeed on any other Q20 page.
This would seem to imply that even though f116 has ended up being bound as the final folio, f115 may well have previously been bound (in a previous binding) as the final folio, with f114 nested just inside it. Additionally, I suspect the absence of matching wormholes on any other Q20 bifolio also weakly implies that at the time when the two outermost bifolios were f114 and f115, none of the other Q20 bifolios was then nested just inside f114. This suggests that the bifolio that was then nested inside f114 might possibly have been the missing Q20 bifolio (f109-f110).
However, from the random bifolio shuffling that seems to have gone on early in the Voynich Manuscript’s life, I’m also fairly certain that when it entered that library, the manuscript was in the form of a set of unbound (or perhaps only very lightly-bound) gatherings. So, even though Wladimir’s wormhole reasoning is sound, I suspect it only takes us back to the manuscript’s wooden cover days, i.e. it doesn’t necessarily tell us about the original bifolio nesting order etc.
All the same, his observation does signal fairly loudly that Q20’s final bifolio order (that we see today) is very likely wrong, giving us confidence that trying to reconstruct the original order is a sensible idea.
Wladimir’s Pre-binding
Wladimir has another interesting observation about Q20. He points out a puncture mark near the bottom of each of the bifolios f103, f104, f105, f106, and f107 (he is unsure from the scans whether or not there is a matching puncture mark on f108, but thinks that there probably is). He describes this as a “pre-binding mark”, where a binder has run a small piece of twine through the bifolios to line them up ready to bind properly.
This would seem to have happened just before the final binding we see today, so it’s quite late on in the overall codicological timeline. However, because there seems to be no evidence of pre-binding elsewhere in the Voynich Manuscript, I can’t help but wonder whether this weakly implies that Q20 was bound separately to the rest of the manuscript.
Vellum Tricks
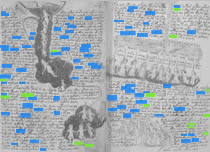
Back in 2016, I posted about the vellum colour of each of the Q20 bifolios. Here, contrast enhanced, are the vellum colours of f103-f116, f104-f115, f105-f114, f106-f113, f107-f112, and f108-f111:
My observation back then was that f103-f116 and f106-f113 seemed different from the others two bifolios: hence it seemed likely to me that the four were cut from a single (large) piece of vellum. It therefore further seemed likely to me that these other four originally sat next to each other.
(Of course, we could do better than my eye by physically sampling DNA from these bifolios and comparing their sequences, but there currently seems to be no appetite for doing this.)
To my mind, this implies that there were probably two quires / gatherings:
- Q20A – f105-f114, f104-f115, f107-f112, and f108-f111
- Q20B – f103-f116 (almost certainly on the outside), f106-f113, and perhaps the middle bifolio
Anton and f105
Voynich researcher Anton [Alipov] (whose name you may recognise from voynich.ninja) commented on Wladimir’s brief summary comment of the above, noting that:
Folio 105 is also somewhat excessively trimmed from the bottom which looks strange.
It’s a neat, clean upward cut across the bottom that continues across to the other half of the bifolio. Without close physical examination (Lisa, have you looked at this?), it’s hard to be sure whether this was in the vellum right from Day One, or whether it was cut off at a later date.
As far as I know, the two main things that typically get added at the bottom of pages are quire numbers and ownership marks. So that suggests to me that there may well have been some ownership mark added to the bottom right of f105r (or the bottom left of f105v) which a later owner wanted to remove. (Not all ownership transfers are transactions later owners want to advertise, as the heavily erased Sinapius signature on f1r seems to attest.)
Similarly, the last folio of Quire 19 (i.e. facing f103r) seems to have had a large chunk taken out of it, which is consistent with an ownership mark there also being excised: this possibly suggests that that may have been the last page of a book / section.
(Incidentally, I pointed out in 2010 that I thought that f105v shows more sign of weathering than just about every other page in Q20, which would seem to imply that it spent a good period of time on the back of the quire. However, looking at f105v again now, I’m not really sure what I was seeing back then.)
This might make the bottom part of f105v the likely location for a quire mark (in one binding), and also the bottom part of f105r the likely location for an ownership mark (in the reversed binding). What a codicological mess!
Unusual Glyph Patterns
Despite its ‘language’ similarities to other Currier B pages, Quire 20 also has a number of glyph pattern idiosyncrasies. In a 2010 comment here, Tim Tattrie pointed out:
“lo” as a separate word is only found in f104r, 106r and 108v.
“rl” as a separate word, or word beginning is only found in f104r, 108v and 113r.
“llo” as a series of letters is only found in f104r, 108v,111v, 113v,116r
Looking at these in voynichese.com, there seem to be just as many free-standing “lo” words in Q13 as in Q20, so I’m not quite taken: and the number of “llo” glyph sequences is extremely low (5 matches).
I’d add that most of the places we see “lr” are in Q20: and similarly for “dl”. There are also some instances of “dr” clustered on f105v, and similarly for “dd”. Q20 is also where the Voynichese glyph “x” appears most often. Sean B. Palmer also thought that the only “genuine” occurrence of “aa” in the Voynich Manuscript was on the third line of f115r (which ends “cholor daar oraro”).
Generally, I do think that the glyph content of Q20 words seems a bit more ‘variable’ than Q13 words, but the overall pattern doesn’t seem wildly different. Unless Rene has some stats on this I don’t know?
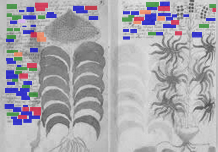
Repairs to f116
An interesting 2015 blog post by David Jackson takes a look at the holes, waterstains and repairs on Q20’s final folio (f116). He speculates (for several different reasons) that f116 was trimmed down to the bare minimum in response to damage to that page.
Broadly speaking, I’m not completely convinced by his argument: the main waterstain (near the top of the folios) is visible all the way through Q20, and vellum – animal skin – is basically waterproof. I think David highlights some interesting features, but they don’t quite fit together for me the way they do for him.
Contact Transfers
There are a few places in Q20 where we can see colour transfers between adjacent pages:
- Paint from the top two red paragraph stars on f116r has transferred to the facing page (f115v)
- Paint from the sixth red star on f113v has transferred past the vellum edge flaw on f114 to f115r
- There’s a stray red paint spot that appears near the top of f104v and f105r
- There’s a stray faint paint spot between f114v and f115r (look between stars #10 and #11)
- Green paint (presumably from Q19?) has ended up on the outer edge of f104r, partly because f103 seems to be about 1cm narrower than f104. (And because f103-f116 is a bifolio, this 1cm different also suggests that the outside edge of f116 was not trimmed down, i.e. that was how that bifolio was originally cut.)
Contact transfers from the paragraph stars highlight the issues of (a) whether the paragraph stars were drawn in the original construction phase, and (b) whether the paragraph stars were painted in the original construction phase – because if they were, then f115v originally faced f116r and f113v faced f115r (with f114 optionally in the middle).
Lisa Fagin Davis’ Scribes
As far as Lisa Fagin Davis’ well-known (and much-cited) scribal analysis of the Voynich Manuscript goes, Quire 20’s palaeography might seem to be one of its less interesting features. She writes (p.17):
The entire Quire is written by Scribe 3 with the exception of folio 115r, where the first twelve lines were written by Scribe 2.
These twelve lines span four short paragraphs, and look like this:
For our present challenge of reconstruct the bifolio nesting order(s) of Q20, all this really does is suggest that f115r might possibly have been the original start of a quire or a section. But you’d almost certainly need to combine this with more information to form the outlines of a proper argument.
Q20 Titles
In Voynich researcher terminology, a “title” is a short sequence of Voynichese text that is positioned on a page in a slightly anomalous (and non-paragraphy) way. For example, everyone knows that f1r (the very first page of the Voynich Manuscript) has four of these ‘titles’ (on lines 6, 10, 21, and 28), a fact that has given rise to the broadly-held speculation that the paragraphs on f1r with titles might be using them to hold section / chapter / book names (in some way). Page f8r similarly has 3 titles (on lines 8, 13, and 21)
Q20 also has some of these Voynichese titles, according to John Grove’s somewhat ancient list:
- f105r, line 9
- f105r, line 36
- f108v, line 52
- f114r, line 34
As with the scribal information, it’s hard to be sure what exactly to make of this: but it certainly makes f105r seem like a page of structural interest, title-wise.
Dictionary Distance Metric
Back in 2010, Julian Bunn posted up an interesting page computing distance metrics between folios in terms of how similar their unique word lists were. I emailed him some comments (which he then incorporated into the web-page) on what this had to say specifically about Quire 20. Here’s what I sent:
Having played with Julian’s results a bit […], it appears that while some pages’ recto and verso sides are very similar, others are wildly different. For example, just in the recipe section:-
103 good
104 very bad
105 very good
106 bad
107 excellent
108 excellent
109 (missing)
110 (missing)
111 excellent
112 good
113 excellent
114 excellent
115 very bad
116 n/a
Looking at pages within recipe bifolios, however, yields different results again: for example, even though both f104 and f115 are both “bad” above (and are on the same bifolio), f104v is extremely similar to f115r, while f104r is extremely similar to f115v (which is a bit odd). Furthermore, the closeness between f111v and f108r suggests that these originally formed the central bifolio (but reversed), i.e. that the correct page order across the centre was f111r, f111v, f108r, f108v. However, f105 / f114 seem quite unconnected, as do f106 / f113 and f107 / f112.
Re-reading my comments 12 years later, it’s clear that there’s quite a lot of suggestive information here. For example, even though the two bifolio pairs f105r/f105v and f114r/f114v are close, the disparity between f105 and f114 weakly suggests that their bifolio sat towards the outside of a quire or gathering.
Similarly, the closeness between the two halves of the f104-f115 bifolio suggests that this may possibly have been a central bifolio (though what precisely is going on remains something of a mystery).
Finally, the fact that f106r/f106v aren’t close but their opposite folio half f113r/f113v are very close suggests that there may have been a change of topic or structure somewhere on f106.
What Have I Missed?
I tried to follow Wladimir’s discussion of Quire 20 “gaskets” (as Google Translate put it), but wasn’t really able to (I believe it’s to do with things attached to the spines of individual quires that were used to bind them to a spine but without gluing them). However, I don’t believe this affects the issue of bifolio ordering I’m trying to tackle here.
I’m unaware of any multi-spectral scans of Q20 that we might be able to refer to so that we can compare the vellum used on different bifolios.
Also, I’m unaware if there are any studies that have specifically used page-to-page word list difference metrics (of the kind Julian Bunn did) to exhaustively evaluate all the different nesting permutations, i.e. to suggest what the original nesting order was.
Regardless, if you know of any other analyses of Q20 that might have some impact on the bifolio nesting order, please mention it in the comment section below, thanks very much!