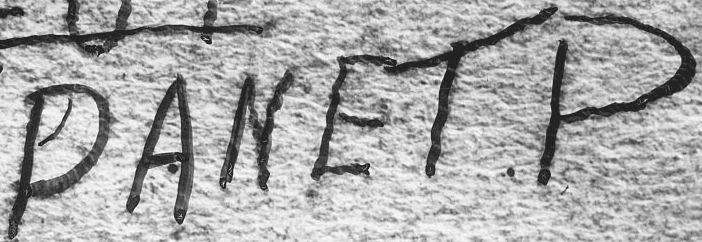Gordon Cramer continues posting apace, asserting – for example – that iodine vapour deposition (also known as “iodine fuming”) and/or UV illumination could have been used in South Australian police forensic photography circa 1948.
But here at Cipher Mysteries Towers, I’m constantly besieged by weak claims built on top of this same “could have” linguistic structure: so it shouldn’t be a surprise that Gordon’s repeated use of it gets my historical goat. In the case of the Somerton Man, “M R G O A B A B D” (or however you want to transcribe it) “could have” also been written by the SM, the nurse, her husband, the person who found the book, saboteurs, conspirators, many thousands of other people that we know nothing about, or indeed by aliens. As with all other cipher mysteries, how does observing that each of these scenarios is ‘possible’ move us forward, exactly?
Then again, Voynich theorist Gordon Rugg has been ploughing that same unyielding field for over a decade now, despite the fact that his possibilistic ard has turned over nothing of value in all that time. So maybe our Tamam Shud Gordon has at least six years’ catching up yet. Hmmmm. 😐
Anyway, by way of sharp contrast, I’ve put a bit of time into trying to understand the specific history of the South Australia Police (SAPOL) and its relationship with forensic photography. What techniques did SAPOL actually use, what evidence is there for this, and what can all that tell us about how the image of the page of the Rubaiyat was taken? As most long-suffering faithful Cipher Mysteries readers doubtless already know, these have the attributes of my favourite kinds of questions: evidence-based, potentially informative, archive-focused, yet in practice tricky to pursue.
So here’s what I found…
The History of SAPOL
South Australia’s policing started relatively early in 1838. Formal police photography didn’t take off in South Australia for many years, even though its Inspector Paul Foelsche took numerous photographs between 1869 and 1914 (these were kept in the family for year, before finally being shown in 1969 to local photographic historian Robert J. Noye).
According to the official SA Police history website…
The first report of [photography] being used in the Police Department was in the late 1870’s, when Detective Von Der Borch was appointed official Photographer. Later a report was submitted requesting a ventilator be installed in the work place to reduce the fumes caused when developing and printing photographs. There is no evidence to show that this science proceeded beyond experimentation until approximately 1898…
..when a certain Detective Lingwood-Smith took on the role: he developed (pun intended) the practical arts of both photography and fingerprinting, turning them into essential parts of police practice, even though the particular fingerprinting scheme he championed was discontinued in 1904. There’s a picture of Lingwood-Smith (inevitably) in the Adelaide ‘Tiser, 29th June 1922, when he claimed that there were “more than 70,000 fingerprints and photographs […] filed in the Adelaide detective office”:-

When asked if he had ever used fingerprint evidence in court, Lingwood-Smith replied that he had not: but that was simply because he had not needed to. “When confronted by their photograph and description, which we have ascertained by means of the finger prints, the offender generally owns up. There is really nothing else for him to do.”
In 1920, Lingwood-Smith passed the baton of the Photography and Fingerprint Section over to Mr. Leslie Hilland Bruce Hudd. In 1923, Bruce Hudd obtained a conviction by ingeniously taking a plaster cast of a footprint left at the scene of a crime: and moreover in 1939…
…he introduced a method for detecting thieves who stole from working companions. A powder was sprinkled onto coins and left at the scene of previous thefts. The powder was not readily visible, and when the money was noticed missing, all staff were requested to place their hands under an ultra violet light. The powder would fluoresce on the hands of the culprit.
Hudd’s photographic and fingerprint evidence was used in a fair number of court cases reported at the time, including the 1942 Hindley Street murders, the Port River murder case of 1944, and a triumphant forensic case from 1947 where a NSW sailor’s badly decomposed (roughly six-month-dead) body was identified purely from his fingerprints. This same article included a picture of Hudd:-

And those who think that the modern forensic study of ears is a new discipline will surely be surprised to read this from the Adelaide News in 1944:-
POLICE fingerprint expert Bruce Hudd is not surprised at a London ear specialist being able to say from a captured German newsreel that the Hitler shown there wasn’t the real Adolf. Today he showed me a book explaining that the shape of the ear doesn’t change from birth to death. Before fingerprint identification came in, the police relied chiefly on ears for identifying men. Fourteen points were set out in describing each ear, including the shape of the lobe, size, and angle to the head. I was shown 140 pictures of ears and saw for myself that not one was alike when an expert pointed out the differences. Even today both Mr. Hudd and Mr. Jimmy Durham, his fellow fingerprint expert, prefer to work on profile pictures showing an ear rather than full face pictures when seeking to identify men.
But even this story pales in relevance to this news piece from 1946, that answers many of my questions directly:-
From there we went to see Mr. Bruce Hudd, chief photographer and fingerprint expert — carefully pulling on our gloves before entering his den. Mr. Hudd said that he now had filed away about 50,000 sets of fingerprints of people who had been brought in on serious charges since 1906. Nowadays he sends a duplicate of all fingerprints to Central Bureau in Sydney, where a master set for the whole of Australia is kept. In Adelaide only one man has tried to beat the fingerprint experts by removing the skin from his fingers. That was the notorious ‘Shiner’ Ryan, who once rubbed the pattern off his fingers on the rough brick wall of his cell, in an effort to outwit expert Hudd. Mr. Hudd waited for the skin to grow again — then took ‘Shiner’s’ prints. Photography is playing a bigger and bigger part in the work of crime detection, and these developments are keeping Mr. Hudd and his staff busy, photographing the scenes of serious crimes, accidents, and copying documents. Ultra-violet light and infra-red rays, which reveal many clues invisible to the naked eye, are now used by the experts of the police photography section.
Incidentally, Hudd was also a dahlia enthusiast (according to Trove), who both grew them and photographed them, hand-tinting the finished product. Now not a lot of people know that. 🙂
Bringing this chapter to close, Hudd finally retired in 1952. He had been assisted in his career “by the following fingerprint experts: Frank Brice, James Durham, Alan Cliff, Dudley Aebi and Bill Low[e]”, which presumably included the three fingerprinting and photographic experts “who did nothing else and their skill was said to be second to none in Australia” back in 1932. On Hudd’s retirement, it was Aebi became the head of the department which he had first joined in 1934, with Bill Lowe also promoted beneath him.
[And yes, it was indeed Constable Patrick James “Jimmy” Durham, stationed in Adelaide, who on 3rd December 1948 took the Somerton Man’s fingerprints in the morgue, and who – with Mounted Constable Knight – then partially re-dressed the Somerton Man and photographed him too. (Feltus, “The Unknown Man”, p.42).]
The South Australian Police History Museum
Even though we have some great – and very specific – description above, I’d still really like to look directly at the South Australian Police photography archives. These are (I believe) held at the volunteer-run South Australian Police History Museum at Thebarton Police Barracks, Gaol Road, Adelaide.
They have placed lots of nice old photographs on its website, most notably transport themed ones here, a few outback ones here, firearms closeups, and uniforms.
However, none of these is the kind of evidential photography apparently used in the Somerton Man case. But there must – surely – be something in there that is similar in technique, that will help us read and reconstruct the precise science of the Rubaiyat ‘code’ photograph?
PS: Victoria Police museum has a vampire-killing kit in its collection, though they don’t put it on display because it doesn’t fit any of their thematic displays. Who’d be a curator, eh?

PPS: here’s something for Pete Bowes I found in “Hue & Cry”, January 2001 edition. “The Murray Pioneer October 20, 1949 DEVICE IN TREE: A parachute with a box attached was found in a gum tree on Calperum Station property, about nine miles from Renmark on Monday morning by Mr W Letton. He reported the matter to the police and Detective DO Flint and MC Brebner went out and recovered the apparatus and handed it to the local Post Office.”
PPPS: has anyone read “The Life and Times of an Unlikely Detective”, by Arthur Robert (Bob) Calvesbert?