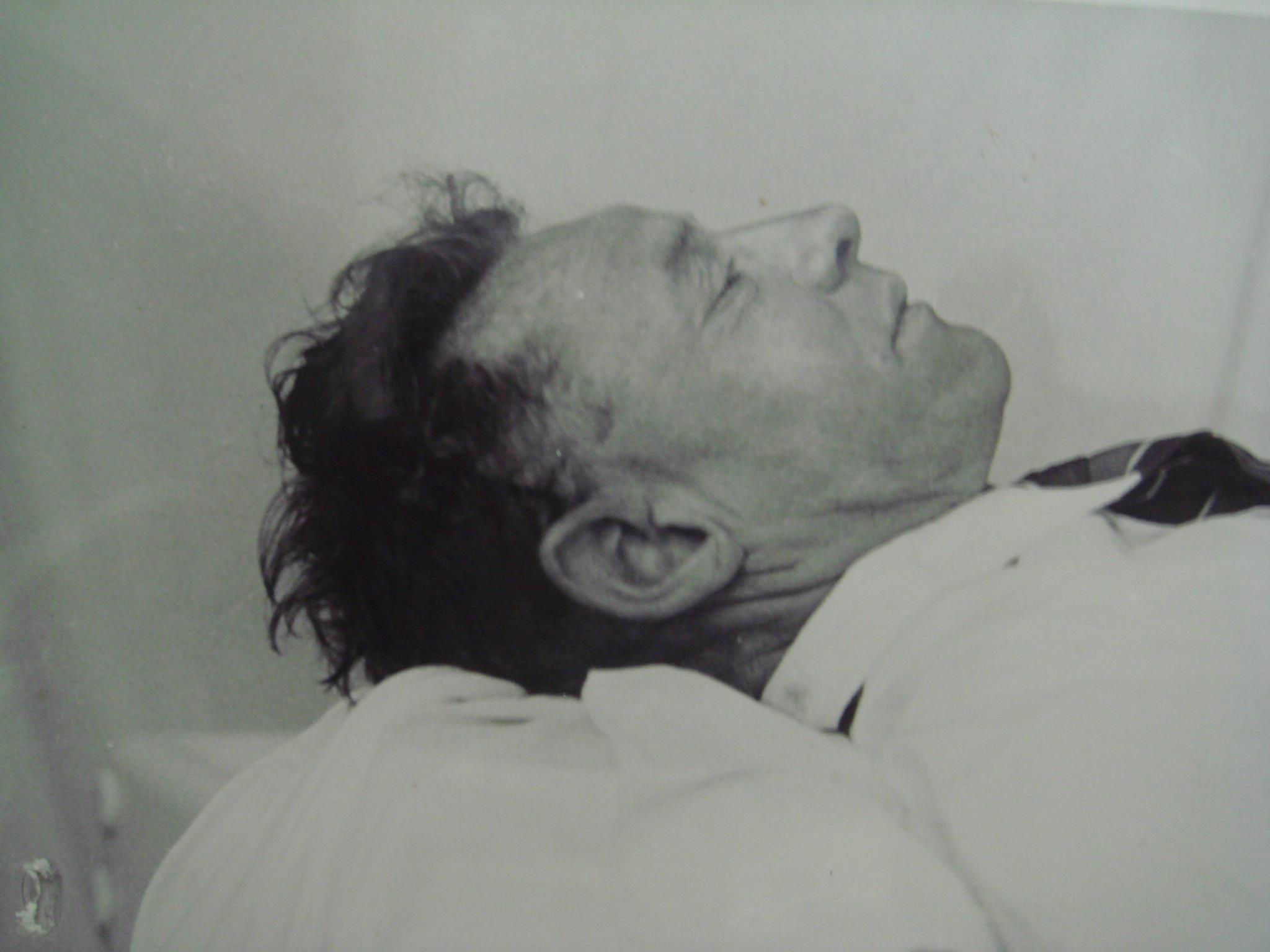
From almost the start of the 1948 investigation into the Somerton Man, South Australian police suspected that he (a) might have worked as a Third Officer on a merchant ship, and (b) might originally have come from Eastern Europe. Add to this his connection with a nurse living in Glenelg who later claimed to have spoken Russian when she was younger, and you get what I think is a reasonably meaty hypothesis to work with – that he was a Russian merchant seaman.
But because he had an American comb, some clothes with American stitching, and a pack of Juicy Fruit chewing gum, it also seems that he had visited America (or perhaps have some long-standing fascination with it). So how might all these pieces link together?
One fascinating maritime connection between the USA and USSR from around this time is the Lend-Lease program, which was launched by the Lend-Lease Act of 11th March 1941: note that the USA was still (theoretically) neutral then, because it did not officially join the war until 8th December 1941, the day after the Japanese attack on Pearl Harbour.

Though Lend-Lease started a lot slower than had been intended (and there are plenty of theories about why this should have been so), it lasted until 1945 and covered all manner of items… on a truly epic scale, as per the following alphabetic list (which I found here):-
- Airplanes 22,150 units; Anti-submarine ships 105 ships; Army shoes 15,417,000 pairs;
- Building equipment in total cost US Dollars 10,910,000; Blankets 1,541,590 pieces; Buttons 257,723,498 pieces;
- Cars 51,503 units; Chemicals 842,000 tons; Cotton 106,893,000 tons;
- Detonators 903,000 units;
- Explosives 295,600 tons;
- Foodstuffs 4,478,000 tons;
- Gasoil 2,670,000 tons;
- Locomotives 1,981 units; Leather 49,860 tons;
- Motorcycles 35,170 units; Machinery in total amount US Dollars 1,078,965,000;
- Non-ferrous metals total 802,000 tons;
- Pistols 12,997 pieces;
- Rifles 8,218 pieces; Railways cars 11,155 units; Radar 445 units;
- Sub-machine guns 131,633 pieces; Ship’s Engine 7,784 units; Spirits 331,066 liters; Cargo Ships – 123 units;
- Tanks 12,700 units; Trucks 375,883 units; Tractors 8,071 units; Torpedo 197 units; Tires 3,786,000 pieces;
(In fact, Russia finally settled its Lend-Lease debt only in August 2006, but that’s another story entirely.)
This vast array of items travelled on at least 123 Lend-Lease ships, and by a variety of sea routes:-
- Pacific 8,244,000 tons (47.1% of total volume);
- Caspian via Iran 4,160,000 tons (23.8%);
- Arctic 3,964,000 tons (22.6%);
- Black Sea 681 tons (3.9%);
- Soviet Arctic Route 452,000 tons (2.6%);
- Grand Total 17,501,000 tons (i.e. 100.0%).
For the Pacific Route (which I suspect is what we’re most interested in), ships departed ports on the USA’s west coast (“principally Los Angeles, San Francisco, Seattle, and Columbia River ports”). The Japanese would often intercept and examine ships on this route, because as part of the USSR-Japan Neutrality Pact, it could not be used for military cargo. These ships usually docked in the heavily-congested port of Vladivostok, before having their cargo carried 5,000 miles West by the Trans-Siberian Railway.
Also as part of this agreement, Japan only allowed the USA-supplied ships used on the Pacific route to be crewed with Russians. Crew was typically a mix of USSR merchant seamen and poorly paid USSR Navy armed guards.
Unlike the Atlantic crossing, Pacific Lend-Lease ships usually sailed individually rather than in convoy: but they were in greatest danger from submarines – German, Japanese, and American submarines all sank some Russian ships (sometimes deliberately, sometimes accidentally).
Incidentally, one of the most famous Lend-Lease Pacific sea captains was Anna Shchetinina, who wrote a book about her experience called “On the Seas and Beyond the Seas” («На морях и за морями») (though after WW2 she worked in the Baltic).
Might the Somerton Man have been a Soviet seaman from a merchant ship that was lost in WW2? I found a list of Soviet ships that were lost in the Pacific: but the only one with unaccounted seamen seemed to be the Uzbekistan (though this ship is marked as “Redelivered” in a different list):-

01.04.1943 – Uzbekistan (Узбекистан – one of USSR republics); Cargo ship / Far East State Shipping Company / 3400 BRT / North Western Coast USA / Wrecked / No information about losses.
Or possibly the Ilich (which doesn’t appear on the list of Lend-Lease ships, so probably wasn’t one):-

4.06.1944 – Ilich (Ильич – Second name of Lenin); Cargo passenger ship / 4166 BRT / Far East State Shipping Company / Capt.I.S.Sergeev / Port of Portland, USA / She sank alongside of berth due to unknown reasons / 1 crew (A.Arekhpaeva) was lost and 66 crew were rescued.
Or perhaps even Soviet submarine L-16, which was torpedoed by Japanese submarine I-25 on October 11, 1942 “on the approach to San Francisco while sailing in surface position, and sank.” More detail on this very interesting (and well-illustrated) page.

I really don’t know: at this stage, I’m just starting to find my way around this little slice of 20th century history, so this is more of a research log than a cipher history post. But I thought you’d like to see what’s going on here. 🙂
* * * * *
Other links and books:-
State archive of Primorsky Territory
Russian State Historical Archive of the Far East – where it is, how to use it
Records of the United States Maritime Commission
Major Jordan’s Diaries (online)
“Feeding the Bear: American Aid to the Soviet Union, 1941-1945”, Hubert P. van Tuyll: Greenwood. ISBN 0-313-26688-3.