Though the whole idea of metal-clad airships sounds like a steampunk fantasy, they were in fact completely real – the US Navy famously commissioned one (the ZMC-2), and plenty of people tried (and indeed even to the present day continue to try) to build others. And the wonder-stuff that made them possible was that marvellously lightweight metal aluminium.
Here’s my brief guide to the whole genre, plus my thoughts on the 1897 Airship “flap”…
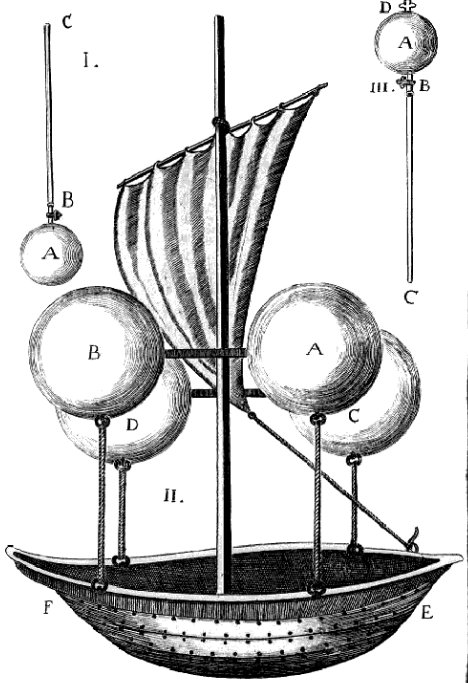
Francesco Lana de Terzi
Historically, the first glimmering of metal-clad LTA (Lighter-Than-Air) flight came circa 1670 (according to Wikipedia) from Francesco Lana de Terzi. He theorised that evacuated metal spheres could provide sufficient lift to float an airship. In reality, if he had built such rigid metal spheres, they would have collapsed under air pressure, but to be fair this was a decent first attempt. And the diagram was cool.
David Schwarz’s Two Airships
By the late 19th Century, materials and technologies had advanced so much that metal airships started to become a genuine possibility. In the 1880s, both the Russian rocket theorist Konstantin Tsiolkovsky and self-taught Croatian engineer David Schwarz realised that a technological sweet spot had opened up. This was building an airship using aluminium (which had been first announced in 1825, and put into industrial production in 1856) and hydrogen (the first hydrogen-filled balloon had flown in 1783).
In 1893, Schwarz produced a test airship for the Russian Army (funded by industrialist Carl Berg) in St Petersburg. The Russian engineer Kowanko pointed out (rightly) that the design’s lack of a ballonet (an extra air bag inside the frame, used to control buoyancy, particularly at take-off) would put a great deal of strain during take-off and landing. And this is indeed what happened – the whole framework collapsed during inflation.
In 1895-7, Schwartz and Berg then built a second airship (this time for the Royal Prussian Government) at the Tempelhof field in Berlin. A test flight in October 1896 was unsuccessful because the hydrogen supplied had been insufficiently purified (and hence provided too little lift). Sadly, Schwartz died (in June 1896, aged 44) before his second metal airship was actually launched: the maiden flight was on 3rd November 1897.

Unfortunately, largely because of structural defects, the airship got no higher than 130m before a combination of problems brought it crashing down, damaging it beyond repair. But… it definitely did fly.
As an aside, Count von Zeppelin later bought all the aluminium used in the ship to reuse in his own (non-metal-skin) zeppelins: the legal agreement he had to sign to do this later gave rise to the myth that he had bought the design rights (which wasn’t true at all).
The 1897 Airship “Flap”
The (ever entertaining, but more than occasionally unreliable) journalist John Keel once wrote a book called “Operation Trojan Horse”. This described a long series of sightings in many US states of a strange airship, almost always travelling by night. This is now generally known as the 1896-1897 airship flap. Keel was convinced that it was, ummm, aliens wot dun it: but given that the descriptions of the people involved tend to be beardy and gentlemanly, this does seem a bit of a stretch.
More recently, Michael Busby’s (2004) “Solving the 1897 Airship Mystery” [I bought the Kindle edition for a very reasonable £4) revisits mainly the Texas sightings from this flap, and draws quite different conclusions.
For example, one contemporary press report gave the names of two men on board the mysterious airship as “S. E. Tillman and A. E. Dolbar”, working for “certain capitalists of New York”. Busby thinks these are Professor Amos Emerson Dolbear and Captain Samuel Escu Tillman; and speculates that the New York capitalists could well have included (gasp) William Randolph Hearst.
Interestingly, a photograph allegedly of the airship taken by a Walter McCann was printed on the front page of the Chicago Tribune, April 12 1897, and also in the Chicago Times-Herald (which I found here):

Might these have been sightings of a metal-clad airship?
C. A. Smith of San Francisco
Matt Novak’s Paleofuture blog mentioned a 1st September 1896 article in the San Francisco Call, reporting that a “Dr C. A. Smith of San Francisco” had a zinc model on display in Market Street of the aluminium & hydrogen airship he hoped to get funding to build. This model had “two wings like those of a beetle” which raised and fell every hundred turns of the airship’s main propeller, along with windows and a door. [Michael Busby’s chapter 19 also includes a 25th November 1896 interview with Smith in the San Francisco Call.]
Some of the observers of the airship reported widely in the 1896-1897 Texas “flap” (see for more about this) described an object having wings “something like that of a bat”. Curiously, C. A. Smith’s 1895 patent includes this drawing, including a distinctive pair of arched bat-like wings pivoted on each side:
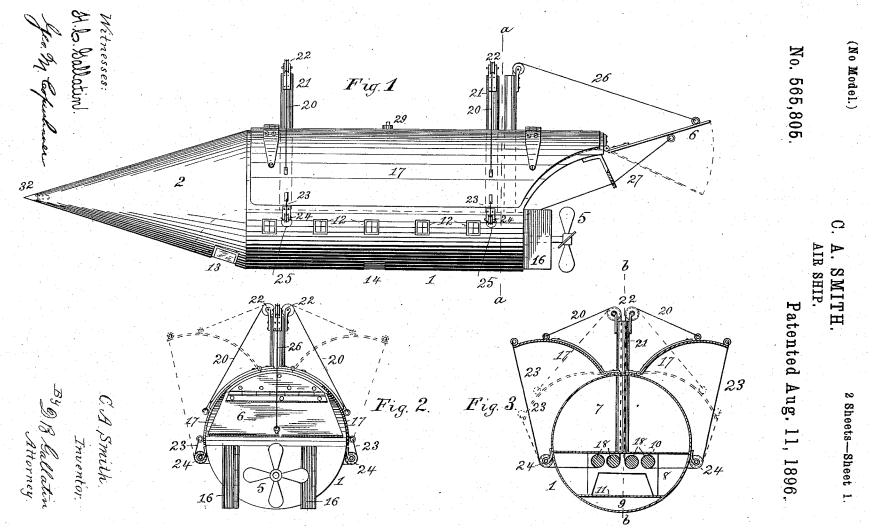
At the end of his book, Busby has little doubt that what was seen flying at night in Texas and elsewhere during 1897 was [spoiler alert] C. A. Smith’s airship, just as Smith had promised in 1896. Busby further speculates that Smith (working in California) may have been a member of Charles Dellschau’s mysterious (and possibly hallucinatory) Sonora Aero Club (here’s a link to a nice story about Dellschau in The Atlantic). But… that’s just Busby’s guess, as far as I can tell.
Sumter B. Battey
Still, when a young C. G. Williams (according to a letter in the Dallas Morning News, April 19 1897) allegedly got to speak with the beardy gentleman flying the airship in Texas, the man claimed to have been developing it for many years “at a little town in the interior of New York state”.
This is perhaps where I should add that a 1900 edition of the Badminton Magazine of Sports and Pastimes included a long list of inventors promoting their airships (“navigable balloons”), including a Mr Sumter B. Battey of New York:
C. E. Hite of Philadelphia, John S. Praul of the same city, J. S. Cowden of Virginia, Carl Erickson, Dr C. A. Smith of San Francisco, and Sumter B. Battey of New York. […] Mr Battey’s idea, for instance, consisted of a cigar-shaped balloon of thin aluminium, assisted by wings for upward or downward flight ; the whole thing to be propelled by a series of explosions. At the rear end was a sort of cup opening outward. Into this pellets of nitro-glycerine were to be dropped and exploded at the rate of six a minute, and the ship was to be propelled by the shocks. Mr Battey’s idea is still on the market. Mr Praul’s machine was to have been made of nickel steel and aluminium throughout, including the cylinder or balloon. [p. 429]
Sumter Beauregard Battey of New York patented a neat-looking design for electric bicycles in 1895, so it should be no huge surprise that he also had an airship patent application that was accepted in 1893.
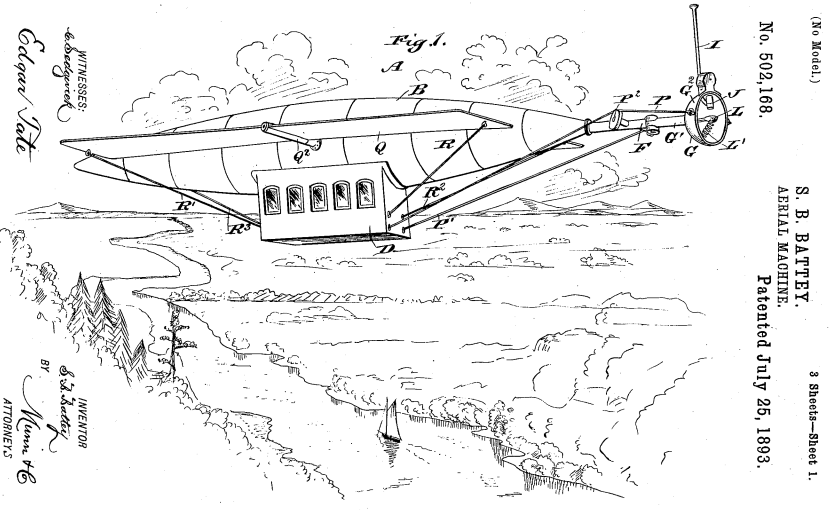
For me, the one oddly distinguishing feature of the airship(s) described in almost all accounts of the 1897 flap was a bright light, much like an electric arc light on the front of the train. So, my own tentative theory – for what it’s worth, and I haven’t seen this mentioned anywhere else – is that what observers took to be a bright light may well have instead been the parabolic dish at the back of the airship that was so distinctive of Battey’s patented propulsion system.
Might Battey’s airship have been the source of the 1897 flap? Though I don’t know so, I think so: if ever there was a nice candidate for a Secret History documentary, this is surely it. My inbox awaits offers from the History Channel etc.
Incidentally, Battey’s address in 1918 (when his son Lieutenant Bryan Mann Battey was reported as missing in action) was “700 West One hundred and seventy-ninth street, New York, NY”, he lived 1861-1934, and his partner was Sarah Angie French. Battey isn’t mentioned in Tom Crouch’s “The Eagle Aloft”, or indeed in any airship history I’ve seen, but perhaps there’s a secret history of airships discussing Battey that I’ve yet to see. Though “Dr S. B. Battey” was a member of the Aeronautic Society of New York, and gave a talk (in 1908?) on wings on dirigibles, please let me know if you see him mentioned anywhere.
Thomas B. Slate’s “City of Glendale”
The 1920s brought a new wave of interest in making metal-clad airships not just possible, but commercially viable. Perhaps most notably, in 1921 Carl B. Fritsche founded the Metalclad Airship Corporation of Detroit (“MAC”), the company that built (as I’ll cover in a separate blog post) the ZMC-2.
But MAC was far from alone. The August 1940 edition of Flying Magazine included an article by J. Gordon Vaeth called “The Blimp Business“, which described a number of other companies who had tried to build metal-clad airships in the 1920s and 1930s.
Thomas B. Slate started up the American Mechanical Engineering Company (an “outgrowth of the Slate Aircraft Corporation”), which in 1928 built an all-metal airship called the “City of Glendale” (“in honor of the city in which it was built” [p.38]).

Though it flew tethered (i.e. as a captive balloon), the Great Depression prevented it from being finished and used commercially: and it was eventually destroyed in 1931. Gordon Vaeth’s description seems to betray a sad fondness for this airship, in that it had a beautifully simple and robust design that could be easily replicated, but that its commercial timing was catastrophically bad.
Carl B. Fritsche and Ralph Upson: the ZMC-2
The history of the ZMC-2 is a huge topic, and this post has already overrun my original target by a factor of 2x or more. So please don’t be cross with me for postponing this to a later date!
National Airship Association of California & Inter-Ocean Dirigible Corporation
Finally, Vaeth’s 1940 article mentions two other companies trying to build radical new metal-clad airships at his time of writing. The first was an all-metal airship designed by Thad Rose for the National Airship Association of California, that had “a prototype under construction”. This contained a clever central tube running down the middle of the airship, creating a vacuum at the front of the ship, pulling it forward. A Russian website I found points to a large article in the April 6, 1939 Los Angeles Times (which I haven’t yet seen), plus a screen-grab of Rose’s 1930 patent. You can see the distinctive power tube running down the centre:
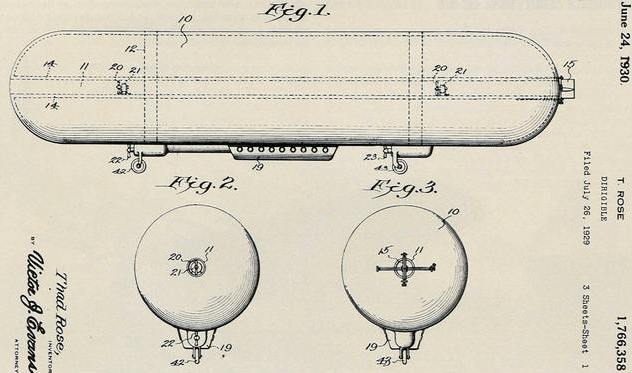
The second was the Inter-Ocean Dirigible Company, which was a Virginia-based company that grew out of the Virginia Airship Company. This, too, incorporated a central (internal) power tube running from end to end: special nozzles at the inlet and outlet of the power tube “enable[d] control of the ship in any direction”. Sadly, I haven’t yet found a patent drawing or picture of this particular airship; but there’s a good chance that it was never actually built.
Your Thoughts, Nick?
The neat-and-tidy Wikipedia page on metal-clad airships is all very well, but I do suspect the succession of airships described above points to a much more interesting history. And who knows, perhaps this will also include the secret history of the 1897 airship flap?